
 pip install -U ultralytics
pip install -U ultralytics
Introdução

A detecção de objetos é um campo fascinante que ganhou muita atenção nos últimos anos devido à sua ampla gama de aplicações em áreas como carros autônomos, sistemas de segurança e assistência médica. YOLOv8 (You Only Look Once versão 8) é um modelo de detecção de objetos de última geração que se tornou cada vez mais popular devido à sua alta precisão e velocidade de processamento rápida. Neste guia para iniciantes, exploraremos as etapas envolvidas no treinamento de um modelo YOLOv"8" do zero, incluindo preparação de dados, configuração do modelo e treinamento. Seja você um iniciante em aprendizado profundo ou um praticante experiente, este guia fornecerá uma base sólida para treinar seu próprio modelo YOLOv8 e explorar o campo emocionante da detecção de objetos.
Para treinar um modelo de detecção de objetos YOLOv8, você deve ter um DataSet de imagens anotadas que indiquem a localização dos objetos que você deseja que o modelo detecte. Embora DataSet de código aberto como COCO e Pascal VOC estejam disponíveis, um DataSet personalizado pode ser mais preciso para seu caso de uso específico. Dividir o DataSet em conjuntos de treinamento e validação também é uma etapa crucial para garantir a precisão e a confiabilidade do seu modelo.
Este blog tem como objetivo orientá-lo por todo o processo de treinamento e avaliação do seu próprio modelo YOLOv8. Forneceremos uma introdução aos recursos do YOLOv8 e discutiremos como anotar e preparar seu DataSet para treinamento. Em seguida, nos aprofundaremos no aspecto importante do treinamento do modelo, fornecendo instruções passo a passo para treinar seu modelo YOLOv8 do zero. Por fim, explicaremos como avaliar o desempenho do seu modelo, fornecendo todo o conhecimento necessário para começar a detecção de objetos usando o YOLOv8. Seja você novo na detecção de objetos ou esteja procurando melhorar suas habilidades, este guia abrangente o equipará com as ferramentas necessárias para treinar um modelo de detecção de objetos YOLOv8 com confiança.
Introdução
YOLOv8 "é" a versão mais recente e melhor da família YOLO (You Only Look Once) de modelos de detecção de objetos em tempo real. Desenvolvido por Glenn Jocher e a equipe da Ultralytics, o YOLOv8 representa uma revisão completa de seus predecessores e ostenta melhorias significativas em velocidade e precisão. Na verdade, o YOLOv8 alcançou resultados de última geração em detecção de objetos em uma variedade de DataSet, incluindo os conhecidos benchmarks COCO e Pascal VOC.
Então o que torna o YOLOv8 tão especial? Sua arquitetura! O YOLOv8 alavanca uma nova rede de backbone chamada CSPDarknet, que usa conexões parciais entre estágios para melhorar o fluxo de informações e a reutilização de recursos. Além disso, ele integra técnicas de ponta como Módulos de Atenção Espacial e funções de ativação Swish para aumentar ainda mais a precisão da detecção de objetos. Tudo isso mantendo velocidades de inferência em tempo real de até 140 quadros por segundo em uma única GPU, tornando-o um dos modelos de detecção de objetos mais rápidos e precisos que existem. Se você está procurando desenvolver aplicativos em campos como veículos autônomos, robótica ou sistemas de vigilância, o YOLOv8 definitivamente vale uma olhada mais de perto.
DataSet e ferramenta de anotação
A base de qualquer projeto de detecção de objetos bem-sucedido é um DataSet bem curado. O DataSet fornece ao modelo as informações necessárias para reconhecer e localizar objetos com precisão. Portanto, antes de mergulhar no treinamento do modelo, é crucial reunir ou criar um bom DataSet que cubra uma ampla gama de cenários e variações que você prevê que o modelo encontrará no mundo real.
DataSet personalizados desempenham um papel crítico na obtenção de alta precisão e especificidade em tarefas de detecção de objetos. Embora vários DataSet de código aberto estejam disponíveis, como o DataSet COCO e o DataSet EgoHands, criar um DataSet personalizado que atenda ao seu caso de uso específico pode ser mais eficaz. Ferramentas de anotação como LabelImg e Roboflow podem ajudar na criação de tal DataSet No intitulado “Construindo modelos precisos de detecção de objetos com RetinaNet: um guia passo a passo abrangente” , utilizei o LabelImg para anotação de imagem. No entanto, neste blog, demonstrarei como usar o Roboflow, uma ferramenta de anotação poderosa que pode agilizar o processo de preparação do DataSet.
Roboflow é uma plataforma de gerenciamento de dados tudo-em-um projetada para tarefas de visão computacional, como detecção de objetos, classificação de imagens e segmentação. Ela oferece uma gama de ferramentas para anotação de imagens, geração de DataSet e implantação de modelos. Com suas integrações com frameworks populares de aprendizado profundo como TensorFlow e PyTorch, o Roboflow facilita o treinamento de modelos usando seu DataSet personalizado.
Um dos recursos de destaque do Roboflow é sua ferramenta intuitiva de anotação de imagens baseada na web. A ferramenta permite que você rotule imagens com caixas delimitadoras, polígonos e outras formas que indicam a localização de objetos na imagem. Sua interface amigável e eficiência facilitam a rotulagem de grandes DataSet de forma rápida e precisa. Além disso, o Roboflow oferece vários recursos para gerenciar DataSet, incluindo aumento de dados, limpeza de dados e exportação de dados. Ele também fornece opções de pré-processamento, como redimensionamento e normalização, que podem melhorar o desempenho do modelo.
No geral, o Roboflow é uma ferramenta excelente para preparar e gerenciar DataSet personalizados para tarefas de visão computacional. Seus recursos abrangentes e interface amigável o tornam ideal tanto para iniciantes quanto para profissionais experientes. Para começar a usar o Roboflow, crie uma conta e configure um novo espaço de trabalho para começar a criar novos projetos.
Após criar um novo projeto no Roboflow, você pode começar a carregar as imagens que deseja anotar. O processo é simples e fácil de seguir. Você pode carregar imagens diretamente do seu computador ou de serviços de armazenamento em nuvem, como Google Drive ou Dropbox. Depois que as imagens forem carregadas, você pode começar a anotá-las usando as poderosas ferramentas de anotação da plataforma. Um exemplo do processo de upload pode ser visto na imagem abaixo:








Após carregar suas imagens no Roboflow, o próximo passo é atribuí-las para anotação. A anotação é um processo crucial na criação de um DataSet personalizado, e o Roboflow facilita isso com sua interface intuitiva. Basta desenhar caixas delimitadoras ao redor dos objetos de interesse, e a ferramenta salvará automaticamente as anotações. Depois de anotar suas imagens, uma caixa de diálogo aparecerá, permitindo que você divida as imagens em conjuntos de treinamento, validação e teste. É recomendável ter pelo menos 60–70% dos seus dados como dados de treinamento, pois isso fornece ao modelo exemplos suficientes para aprender. No entanto, a divisão pode ser ajustada para atender às suas necessidades específicas. Com a ferramenta de anotação do Roboflow e os recursos de gerenciamento de dados fáceis de usar, criar um DataSet personalizado para tarefas de detecção de objetos nunca foi tão fácil.




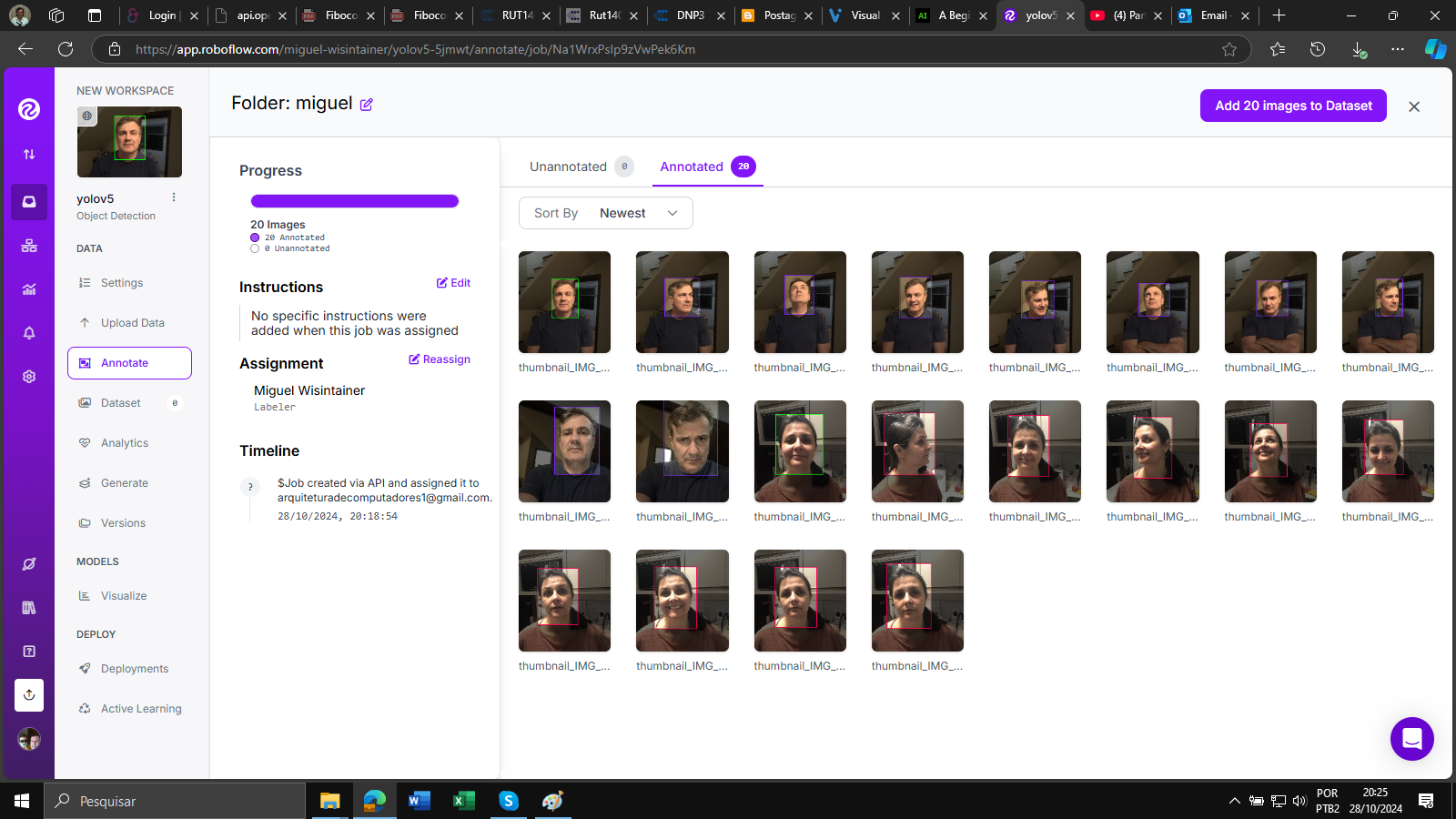

Após concluir o processo de anotação, você pode criar um DataSet dividindo as imagens anotadas em conjuntos de treinamento, validação e teste (train, valid, test):

Após adicionar imagens ao DataSet e anotá-las, a próxima etapa é gerar uma nova versão do DataSet para exportar para seu IDE local ou Google Colab.
train-yolov8-obb.ipynb - Colab
Durante o processo de geração, você pode escolher as etapas de pré-processamento e aumento de acordo com seus requisitos. Por exemplo, você pode redimensionar as imagens ou aplicar técnicas de aumento de dados, como rotação ou inversão, para aumentar a diversidade do DataSet. Assim que o processo de geração for concluído, você pode exportar facilmente seu DataSet e usá-lo para treinar seu modelo de detecção de objetos.











Após gerar uma nova versão do DataSet, o próximo passo é exportá-lo em um formato adequado para treinar o modelo. O Roboflow oferece a flexibilidade de exportar o DataSet em vários formatos, incluindo o formato YOLOv8 Pytorch (.pt), que usaremos neste exemplo. Este formato é amplamente usado para treinar modelos de detecção de objetos e é compatível com estruturas populares de aprendizado profundo (Deep Learning), como o PyTorch. Depois de selecionar o formato de exportação desejado, o Roboflow gerará um link de download para o DataSet exportado. Você pode usar este link para baixar o DataSet para seu IDE local ou Google Colab para processamento e treinamento adicionais.

É crucial salvar o link de download gerado após exportar seu DataSet em um arquivo de texto para fácil acesso, especialmente se você planeja usá-lo em um notebook do Google Colab.

O arquivo gerado foi o yolov5.v1i.yolov8.zip, apesar do 5, é o 8.
Agora que preparamos nosso DataSet, é hora de mergulhar na parte emocionante do processo de detecção de objetos: treinar o modelo. Esta etapa é onde o algoritmo aprende a identificar e classificar objetos em imagens, permitindo que ele faça previsões precisas em dados não vistos. Então, vamos começar!
Treinamento de modelo
Neste artigo, usaremos o Colab para treinar o modelo de detecção de objetos YOLOv8 em nosso DataSet personalizado. O Google Colab é uma plataforma poderosa e fácil de usar para treinar modelos de aprendizado profundo. O primeiro passo para começar a usar o YOLOv8 no Colab é clonar o repositório GitHub do YOLOv8. Este repositório contém todo o código e os arquivos de configuração necessários para treinar o modelo. A clonagem do repositório pode ser feita executando um comando simples no notebook do Colab:
train-yolov8-obb.ipynb - Colab

!pip install ultralytics==8.2.103 -q
Após clonar o repositório YOLOv8 GitHub, precisamos configurar o ambiente e configurar o modelo para treinamento. Isso envolve várias etapas, como instalar as dependências necessárias, configurar os caminhos para o DataSet e os arquivos de configuração do modelo e especificar os parâmetros de treinamento, como tamanho do lote, taxa de aprendizado e número de épocas.
Para instalar as dependências necessárias, precisamos alternar para o diretório YOLOv8 usando o %cd yolov8comando no notebook Colab. Para confirmar que estamos no diretório correto, podemos import osmodular e executar o comando print(os.getcwd())para imprimir o diretório de trabalho atual. Isso garante que estamos no lugar certo para executar o script de treinamento para nosso modelo YOLOv8.
import osHOME = os.getcwd()print(HOME)
/content


----------------------------------------------------------------
Também pode ser feito no modo automático




----------------------------------------------------------------
"Unzip" o arquivo ZIP


Iniciar o treinamento
Consulte o data.yaml e você verá o seguinte conteúdo, são 2 conjuntos de imagens que devem ser treinadas, de andreia e miguel.
from ultralytics import YOLO
model = YOLO('yolov8n.pt')
results = model.train(data=f"data.yaml", epochs=100, imgsz=640)

Neste comando, podemos especificar os seguintes parâmetros:
--img: O tamanho das imagens de entrada durante o treinamento. Aqui, estamos configurando para 640x640 pixels.--batch: O tamanho do lote para treinamento. Aqui, estamos definindo-o como 8.--epochs: O número de épocas para treinar. Aqui, estamos definindo para 100.--data: O local do arquivo YAML do DataSet que criamos no Roboflow.--weights: A localização dos pesos do modelo YOLOv8 pré-treinados. Aqui, estamos usando oyolov8n.ptarquivo.--cache: Se as imagens devem ou não ser armazenadas em cache para um treinamento mais rápido.
Depois que executarmos esse comando, o processo de treinamento começará e poderemos monitorar o progresso no notebook Colab.

Durante o processo de treinamento, o YOLOv8 salva dois tipos de arquivos de checkpoint: last.pte best.pt.
last.pté o último checkpoint salvo do modelo. Ele é atualizado após cada época de treinamento e contém os pesos do modelo naquele ponto do processo de treinamento. Este checkpoint pode ser usado para retomar o treinamento de onde ele foi interrompido ou para avaliar o desempenho do modelo em uma determinada época.
best.pté o ponto de verificação que tem a melhor perda de validação até agora. Ele é atualizado sempre que a perda de validação melhora e contém os pesos do modelo naquele ponto. Este ponto de verificação é útil para seleção de modelo, pois representa o ponto no processo de treinamento em que o modelo teve o melhor desempenho no conjunto de validação. Ambos last.pte best.ptpodem ser usados para inferência após a conclusão do processo de treinamento.
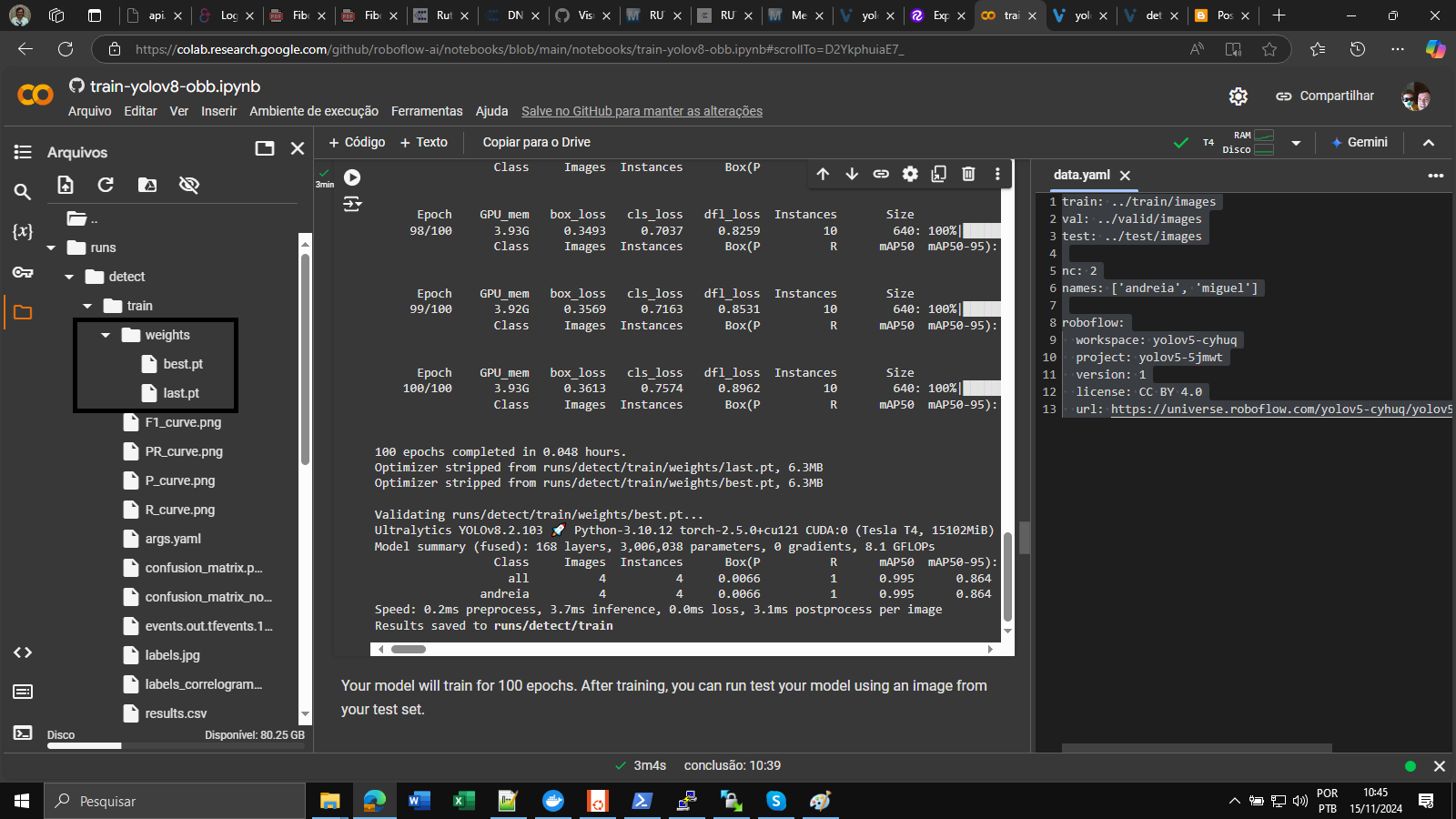
O arquivo .pt pode ser baixado do Google Colab para sua máquina local apenas clicando sobre o mesmo.
Este arquivo contém os pesos do modelo de melhor desempenho durante o treinamento. É importante salvar este arquivo em um local seguro, pois ele representa o modelo treinado e pode ser usado para fazer previsões em novas imagens ou para continuar treinando o modelo mais tarde.
Avaliação de modelo
Escolha a melhor ferramenta que você achar, um exemplo é o TensorBoard, que é uma ferramenta poderosa para visualizar e analisar experimentos de aprendizado de máquina.

Pegando o arquivo gerado e descompactando no COLAB
yolov5.v1i.yolov8.zip
!unzip

Detecção de objetos yolov8 no DUO 256
Este programa de teste inferirá o modelo yolov8 para atingir a detecção de alvos, e os resultados serão exibidos apenas na forma de impressão.
Foi utilizado o WSL2 UBUNTU 22 com DOCKER instalado, ver blogs publicados sobre Yolo5 no site.
Baixe o detector cvimodel pré-compilado
git clone https://github.com/zwyzwm/YOLOv8-Object-Detection.git(apenas para testes com uma imagem já treinada)
YOLO de compilação cruzada do lado do PC do programa YOLO
Localização do código Duo256M yolov8: sample_yolov8.cpp
(o mesmo deve ser compilado para o DUO 256)
Método de compilação
Consulte o método do link Introdução para compilar o programa "sample".
Após a conclusão da compilação, o programa sample_yolov8 que precisamos será gerado no diretório sample/cvi_yolo/
Compilação de modelos
Exportar o modelo do yolov8n.onnx
Tenha o Python acima de 3.8, a versão PyTorch acima de 2.0.1, é melhor usar a versão mais recente
Ativar (por exemplo Python 3.8, torch2.0.1):
pip3 install --upgrade pip
pip3 install torch==2.0.1
Crie um diretório para guardar o yolov8_export.py e também best.pt
mkdir model_yolov8n && cd model_yolov8n (no /workspace)
Copie o código yolo_export/yolov8_export.py para o diretório bem como o best.pt para gerar onnx.
python3 yolov8_export.py --weights ./best.pt --img-size 640 640(best.pt é o que geramos no Colab)

Será gerado o arquivo best.onnx no diretório atual

Explicação do parâmetro
--weights caminho do modelo pytorch
--img-size tamanho de entrada da imagemModelo
Modelo de conversão TPU-MLIR
Consulte o documento TPU-MLIR para configurar o ambiente de trabalho TPU-MLIR. Para análise de parâmetros, consulte o documento TPU-MLIR .
Em /workspace/tpu-mlir/regression/datasetcrie uma pasta HOUSE e coloque as imagens de treinamento criadas pelo Roboflow.

Em /workspace/tpu-mlir/regression/imagecopie as imagens que você pretende fazer a inferência.
 andmig.jpg
andmig.jpg

cp -rf $/workspace/tpu-mlir/regression/dataset/HOUSE .
cp -rf $/workspace/tpu-mlir/regression/image .
A operação é a seguinte:As etapas específicas de implementação são divididas em três etapas:
- model_transform.py converte o modelo onnx no modelo de formato intermediário mlir
onnx -> model_transform.py -> mlir
- run_calibration.py gera tabela de calibração de quantização int8
conjunto_de_calibração -> run_calibration.py -> tabela_de_calibração
- model_deploy.py gera mlir com tabela de quantização int8 para cvimodel para inferência TPU
mlir + tabela_de_calibração ->model_deploy.py -> cvimodel
onnx para MLIR
cd /workspace
model_transform.py \
--model_name yolov8n \
--model_def best.onnx \
--input_shapes [[1,3,640,640]] \
--mean 0.0,0.0,0.0 \
--scale 0.0039216,0.0039216,0.0039216 \
--keep_aspect_ratio \
--pixel_format rgb \
--mlir yolov8n.mlir

Após a conversão para o arquivo mlir, um arquivo yolov8n.mlir será gerado.
Modelo MLIR para INT8 (suporta apenas o modelo de quantização INT8)
run_calibration.py yolov8n.mlir \ --dataset /workspace/tpu-mlir/regression/dataset/HOUSE \ --input_num 40 \ -o yolov8n_cali_table


Use a tabela de calibração para gerar cvimodel simétrico int8
model_deploy.py \
--mlir yolov8n.mlir \
--quant_input --quant_output \
--quantize INT8 \
--calibration_table yolov8n_cali_table \
--chip cv181x \
--model yolov8n_cv181x_int8_sym.cvimodel


Após a conclusão da compilação, um arquivo chamado yolov8n_cv181x_int8_sym.cvimodel será gerado.
(Opcional) Gerar cvimodel assimétrico int8
model_deploy.py \--mlir yolov8n.mlir \--quant_input --quant_output \--quantize INT8 --asymmetric \--calibration_table yolov8n_cali_table \--chip cv181x \--model yolov8n_cv181x_int8_asym.cvimodelApós a conclusão da compilação, um arquivo chamado yolov8n_cv181x_int8_sym.cvimodel será gerado.

Transferindo para Duo 256
Copie o sample_yolov8 compilado, o cvimodel e a imagem jpg a ser inferida, para a placa e execute o programa binário:
scp yolov8n_cv181x_int8_sym.cvimodel root@192.168.42.1:/root/





Com o Putty, entre no DUO 256 e veja os arquivos transferidos.

[root@milkv-duo]~# ls
a.jpg dog.jpg ii.jpg mm.jpg sample_yolov8
aa.jpg e.jpg j.jpg n.jpg t.jpg
andmig.jpg ee.jpg jj.jpg nn.jpg u.jpg
b.jpg f.jpg k.jpg o.jpg v.jpg
bb.jpg ff.jpg kk.jpg oo.jpg w.jpg
c.jpg g.jpg l.jpg p.jpg x.jpg
cat.jpg gg.jpg ll.jpg pp.jpg yolov8n_cv181x_int8_sym.cvimodel
cc.jpg h.jpg m.jpg q.jpg z.jpg
d.jpg hh.jpg mig.jpg r.jpg
dd.jpg i.jpg miguel.jpg s.jpg
[root@milkv-duo]~#
Execute o seguinte comando:
export LD_LIBRARY_PATH='/mnt/system/lib'
./sample_yolov8 ./yolov8n_cv181x_int8_sym.cvimodel image.jpg
O efeito é o seguinte:
tirado pela WEBCAM (andmiguel.jpg)



tirado pela WEBCAM (andreia.jpg)


Dataset
Referência (Tradução) e testes com MILK-V
A Beginner’s Guide to Training a YOLOv5 Object Detection Model | by Prithvi Seshadri | Artificial Intelligence in Plain English
Part3: Face Recognition | YOLOv5 | Step-by-Step Guide
Train Custom Data · ultralytics/yolov5 Wiki · GitHub
Training Yolo v5 on Custom Dataset for Object Detection | Roboflow Universe & Workspace
https://www.youtube.com/watch?v=GRtgLlwxpc4&t=1165s
Train Custom Data · ultralytics/yolov5 Wiki
TFLite, ONNX, CoreML, TensorRT Export - Ultralytics YOLO Docs
yolov8 object detection | Milk-V
6. Deployment of Yolov8 Model for General Use — YOLODevelopmentGuide master documentation
Sobre a SMARTCORE
A SMARTCORE FORNECE CHIPS E MÓDULOS PARA IOT, COMUNICAÇÃO WIRELESS, BIOMETRIA, CONECTIVIDADE, RASTREAMENTO E AUTOMAÇÃO. NOSSO PORTFÓLIO INCLUI MODEM 2G/3G/4G/NB-IOT, SATELITAL, MÓDULOS WIFI, BLUETOOTH, GPS, SIGFOX, LORA, LEITOR DE CARTÃO, LEITOR QR CCODE, MECANISMO DE IMPRESSÃO, MINI-BOARD PC, ANTENA, PIGTAIL, BATERIA, REPETIDOR GPS E SENSORES.
A SMARTCORE FORNECE CHIPS E MÓDULOS PARA IOT, COMUNICAÇÃO WIRELESS, BIOMETRIA, CONECTIVIDADE, RASTREAMENTO E AUTOMAÇÃO. NOSSO PORTFÓLIO INCLUI MODEM 2G/3G/4G/NB-IOT, SATELITAL, MÓDULOS WIFI, BLUETOOTH, GPS, SIGFOX, LORA, LEITOR DE CARTÃO, LEITOR QR CCODE, MECANISMO DE IMPRESSÃO, MINI-BOARD PC, ANTENA, PIGTAIL, BATERIA, REPETIDOR GPS E SENSORES.
Nenhum comentário:
Postar um comentário