{
"github_url":"https://github.com/sophgo/tdl_models/tree/main/",
"_comment":"model_list specify the model maintained in tdl_models,each model should at least have file name and rgb_order(choice:rgb,bgr,gray)",
"model_list":{
"MBV2_DET_PERSON":{
"types":["person"],
"file_name":"mbv2_det_person_256_448_INT8",
"rgb_order":"rgb"
},
"YOLOV8N_DET_HAND":{
"types":["hand"],
"file_name":"yolov8n_det_hand_384_640_INT8"
},
"YOLOV8N_DET_PET_PERSON":{
"types":["cat","dog","person"],
"file_name":"yolov8n_det_pet_person_384_640_INT8"
},
"YOLOV8N_DET_BICYCLE_MOTOR_EBICYCLE":{
"types":["bicycle","motorcycle","ebicycle"],
"file_name":"yolov8n_det_bicycle_motor_ebicycle_384_640_INT8"
},
"YOLOV8N_DET_PERSON_VEHICLE":{
"types":["car","bus","truck","rider with motorcycle","person","bike","motorcycle"],
"file_name":"yolov8n_det_person_vehicle_384_640_INT8"
},
"YOLOV8N_DET_HAND_FACE_PERSON":{
"types":["hand","face","person"],
"file_name":"yolov8n_det_hand_face_person_384_640_INT8"
},
"YOLOV8N_DET_FACE_HEAD_PERSON_PET":{
"types":["face","head","person","pet"],
"file_name":"yolov8n_det_face_head_person_pet_384_640_INT8"
},
"YOLOV8N_DET_HEAD_PERSON":{
"types":["head","person"],
"file_name":"yolov8n_det_head_person_384_640_INT8"
},
"YOLOV8N_DET_HEAD_HARDHAT":{
"types":["head","hardhat"],
"file_name":"yolov8n_det_head_hardhat_576_960_INT8"
},
"YOLOV8N_DET_FIRE_SMOKE":{
"types":["fire","smoke"],
"file_name":"yolov8n_det_fire_smoke_384_640_INT8"
},
"YOLOV8N_DET_FIRE":{
"types":["fire"],
"file_name":"yolov8n_det_fire_384_640_INT8"
},
"YOLOV8N_DET_HEAD_SHOULDER":{
"types":["head shoulder"],
"file_name":"yolov8n_det_head_shoulder_384_640_INT8"
},
"YOLOV8N_DET_LICENSE_PLATE":{
"types":["license plate"],
"file_name":"yolov8n_det_license_plate_384_640_INT8"
},
"YOLOV8N_DET_TRAFFIC_LIGHT":{
"types":["red","yellow","green","off","wait on"],
"file_name":"yolov8n_det_traffic_light_384_640_INT8"
},
"YOLOV8N_DET_MONITOR_PERSON":{
"types":["person"],
"file_name":"yolov8n_det_monitor_person_256_448_INT8"
},
"YOLOV11N_DET_MONITOR_PERSON":{
"types":["person"],
"file_name":"yolov11n_det_monitor_person_384_640_INT8"
},
"YOLOV11N_DET_BICYCLE_MOTOR_EBICYCLE":{
"types":["bicycle","motorcycle","ebicycle"],
"file_name":"yolov11n_det_bicycle_motor_ebicycle_384_640_INT8"
},
"YOLOV5_DET_COCO80":{
"is_coco_types":true,
"file_name":"yolov5s_det_coco80_640_640_INT8"
},
"YOLOV6_DET_COCO80":{
"is_coco_types":true,
"file_name":"yolov6n_det_coco80_640_640_INT8"
},
"YOLOV7_DET_COCO80":{
"is_coco_types":true,
"file_name":"yolov7_tiny_det_coco80_640_640_INT8"
},
"YOLOV8_DET_COCO80":{
"is_coco_types":true,
"file_name":"yolov8n_det_coco80_640_640_INT8"
},
"YOLOV10_DET_COCO80":{
"is_coco_types":true,
"file_name":"yolov10n_det_coco80_640_640_INT8"
},
"YOLOV11N_DET_COCO80":{
"is_coco_types":true,
"file_name":"yolov11n_det_coco80_640_640_INT8"
},
"PPYOLOE_DET_COCO80":{
"is_coco_types":true,
"file_name":"ppyoloe_det_coco80_640_640_INT8"
},
"YOLOX_DET_COCO80":{
"is_coco_types":true,
"file_name":"yolox_m_det_coco80_640_640_INT8"
},
"YOLOV5":{
"_comment":"custom model, specify num_cls or branch string",
"file_name":""
},
"YOLOV6":{
"_comment":"custom model, specify num_cls or branch string",
"file_name":""
},
"YOLOV8":{
"_comment":"custom model, specify num_cls or branch string",
"file_name":"best",
"model_path": "/root/best.cvimodel",
"model_type": "yolov8",
"input_width": 640,
"input_height": 640,
"num_classes": 3,
"threshold": 0.5,
"nms_threshold": 0.45,
"mean": [0.0, 0.0, 0.0],
"scale": [0.00392157, 0.00392157, 0.00392157],
"format": "RGB",
"labels": ["Ades", "Barbie", "Bauer"]
},
"YOLOV10":{
"_comment":"custom model, specify num_cls or branch string",
"file_name":""
},
"PPYOLOE":{
"_comment":"custom model, specify num_cls or branch string",
"file_name":""
},
"YOLOX":{
"_comment":"custom model, specify num_cls or branch string",
"file_name":""
},
"SCRFD_DET_FACE":{
"_comment":"output face and 5 landmarks",
"types":["face"],
"file_name":"scrfd_det_face_432_768_INT8"
},
"CLS_ATTRIBUTE_GENDER_AGE_GLASS":{
"_comment":"output age,gender(0:male,1:female),glass(0:no glass,1:glass)",
"types":["age","gender","glass"],
"file_name":"cls_attribute_gender_age_glass_112_112_INT8",
"rgb_order":"rgb",
"mean":[0,0,0],
"std":[255.0,255.0,255.0]
},
"CLS_ATTRIBUTE_GENDER_AGE_GLASS_MASK":{
"_comment":"output age,gender(0:male,1:female),glass(0:no glass,1:glass),mask(0:no mask,1:mask)",
"types":["age","gender","glass","mask"],
"file_name":"cls_attribute_gender_age_glass_mask_112_112_INT8",
"rgb_order":"rgb",
"mean":[0,0,0],
"std":[255.0,255.0,255.0]
},
"CLS_ATTRIBUTE_GENDER_AGE_GLASS_EMOTION":{
"_comment":"output age,gender(0:male,1:female),glass(0:no glass,1:glass),emotion(0:anger,1:disgut,2:fear,3:happy,4:neutral,5:sad;6:surprise)",
"types":["age","gender","glass","emotion"],
"file_name":"cls_attribute_gender_age_glass_emotion_112_112_INT8",
"rgb_order":"rgb",
"mean":[0,0,0],
"std":[255.0,255.0,255.0]
},
"CLS_RGBLIVENESS":{
"_comment":"output 0:live or 1:spoof",
"types":["live","spoof"],
"file_name":"cls_rgbliveness_256_256_INT8",
"rgb_order":"rgb",
"mean":[0,0,0],
"std":[255.0,255.0,255.0]
},
"CLS_YOLOV8":{
"file_name":"yolov8_cls_384_640_INT8",
"rgb_order":"rgb",
"mean":[0,0,0],
"std":[255.0,255.0,255.0]
},
"CLS_HAND_GESTURE":{
"_comment":"output hand gesture(0:fist,1:five,2:none,3:two)",
"types":["fist","five","none","two"],
"file_name":"cls_hand_gesture_128_128_INT8",
"rgb_order":"rgb",
"mean":[0,0,0],
"std":[255.0,255.0,255.0]
},
"CLS_KEYPOINT_HAND_GESTURE":{
"_comment":"output hand gesture(0:fist,1:five,2:four,3:none,4:ok,5:one,6:three,7:three2,8:two)",
"types":["fist","five","four","none","ok","one","three","three2","two"],
"file_name":"cls_keypoint_hand_gesture_1_42_INT8",
"rgb_order":"rgb",
"mean":[0,0,0],
"std":[1.0,1.0,1.0]
},
"CLS_SOUND_BABAY_CRY":{
"_comment":"output 0:background or 1:cry,single channel",
"types":["background","cry"],
"file_name":"cls_sound_babay_cry_188_40_INT8",
"rgb_order":"gray"
},
"CLS_SOUND_COMMAND_NIHAOSHIYUN":{
"_comment":"single channel,TODO:add types",
"types":["background","nihaoshiyun"],
"file_name":"cls_sound_nihaoshiyun_126_40_INT8",
"rgb_order":"gray",
"hop_len":128,
"fix":1
},
"CLS_SOUND_COMMAND_NIHAOSUANNENG":{
"_comment":"single channel,TODO:add types",
"types":["background","nihaosuanneng"],
"file_name":"my_custom_sound_command",
"rgb_order":"gray",
"hop_len":128,
"fix":1
},
"CLS_SOUND_COMMAND_XIAOAIXIAOAI":{
"_comment":"single channel,TODO:add types",
"types":["background","xiaoaixiaoai"],
"file_name":"cls_sound_xiaoaixiaoai_126_40_INT8",
"rgb_order":"gray",
"hop_len":128,
"fix":1
},
"CLS_IMG":{
"_comment":"custom classification, set types,file_name,specify rgb order and mean/std",
"types":["custom"],
"file_name":"",
"rgb_order":"rgb"
},
"KEYPOINT_LICENSE_PLATE":{
"_comment":"output 4 license plate keypoints",
"types":["top_left","top_right","bottom_left","bottom_right"],
"file_name":"keypoint_license_plate_64_128_INT8",
"rgb_order":"rgb"
},
"KEYPOINT_HAND":{
"_comment":"output 21 hand keypoints",
"file_name":"keypoint_hand_128_128_INT8",
"rgb_order":"rgb"
},
"KEYPOINT_YOLOV8POSE_PERSON17":{
"_comment":"output 17 person keypoints and box",
"file_name":"keypoint_yolov8pose_person17_384_640_INT8",
"rgb_order":"rgb"
},
"KEYPOINT_SIMCC_PERSON17":{
"_comment":"output 17 person keypoints from cropped image",
"file_name":"keypoint_simcc_person17_256_192_INT8",
"rgb_order":"rgb"
},
"KEYPOINT_FACE_V2": {
"_comment": "KEYPOINT_FACE_V2",
"file_name": "keypoint_face_v2_64_64_INT8"
},
"LSTR_DET_LANE":{
"_comment":"output lane keypoints",
"file_name":"lstr_det_lane_360_640_MIX",
"rgb_order":"rgb"
},
"RECOGNITION_LICENSE_PLATE":{
"_comment":"output 7 license plate characters",
"file_name":"recognition_license_plate_24_96_MIX",
"rgb_order":"bgr"
},
"YOLOV8_SEG":{
"_comment":"custom segmentation,set types,file_name,specify rgb order",
"types":[],
"file_name":"yolov8_seg_384_640_INT8"
},
"YOLOV8_SEG_COCO80":{
"is_coco_types":true,
"_comment":"output 80 segmentation mask",
"file_name":"yolov8n_seg_coco80_640_640_INT8"
},
"TOPFORMER_SEG_PERSON_FACE_VEHICLE":{
"_comment":"output mask",
"types":["background","person","face","vehicle","license plate"],
"file_name":"topformer_seg_person_face_vehicle_384_640_INT8",
"rgb_order":"rgb"
},
"FEATURE_IMG":{
"_comment":"custom segmentation,set file_name,specify rgb order,set mean/std",
"file_name":"",
"rgb_order":"rgb"
},
"FEATURE_CLIP_IMG":{
"_comment":"clip image feature extraction",
"file_name":"feature_clip_image_224_224_W4BF16",
"rgb_order":"rgb"
},
"FEATURE_CLIP_TEXT":{
"_comment":"clip text feature extraction",
"file_name":"feature_clip_text_1_77_W4BF16",
"rgb_order":"rgb"
},
"FEATURE_MOBILECLIP2_IMG":{
"_comment":"mobileclip2 image feature extraction",
"file_name":"feature_mobileclip2_B_img_224_224_INT8",
"rgb_order":"rgb"
},
"FEATURE_MOBILECLIP2_TEXT":{
"_comment":"mobileclip2 text feature extraction",
"file_name":"feature_mobileclip2_B_text_1_77_INT8",
"rgb_order":"rgb"
},
"FEATURE_CVIFACE":{
"_comment":"cviface 256-dimensional feature",
"file_name":"feature_cviface_112_112_INT8",
"rgb_order":"rgb",
"mean":[127.5,127.5,127.5],
"std":[128,128,128]
},
"FEATURE_BMFACE_R34":{
"_comment":"output 512 dim feature",
"file_name":"feature_bmface_r34_112_112_INT8",
"rgb_order":"rgb",
"mean":[0,0,0],
"std":[1,1,1]
},
"FEATURE_BMFACE_R50":{
"_comment":"output 512 dim feature",
"file_name":"bmface_r50_v1_bmnetp.bmodel",
"rgb_order":"rgb",
"mean":[0,0,0],
"std":[1,1,1]
},
"TRACKING_FEARTRACK":{
"_comment":"single object tracking",
"file_name":"tracking_feartrack_128_128_256_256_INT8",
"rgb_order":"rgb",
"mean":[123.675,116.28,103.53],
"std":[58.395,57.12,57.375]
},
"RECOGNITION_SPEECH_ZIPFORMER_ENCODER":{
"file_name":"recognition_speech_zipformer_encoder-s_71_80_BF16"
},
"RECOGNITION_SPEECH_ZIPFORMER_DECODER":{
"file_name":"recognition_speech_zipformer_decoder-s_1_2_BF16"
},
"RECOGNITION_SPEECH_ZIPFORMER_JOINER":{
"file_name":"recognition_speech_zipformer_joiner-s_1_512_1_512_BF16"
}
}
}
=================
!!!!!!!!!!!!!!!!!!!!!!!! solucao tdl_sdk !!!!!!!!!!!!!!!!!!!!!!!
em
https://colab.research.google.com/github/roboflow-ai/notebooks/blob/main/notebooks/train-yolov8-obb.ipynb#scrollTo=tdSMcABDNKW-
!pip install ultralytics==8.2.103 -q
faça o upgrade
treine
from ultralytics import YOLO
model = YOLO('yolov8n.pt')
results = model.train(data=f"data.yaml", epochs=100, imgsz=640)
https://github.com/milkv-duo/duo-buildroot-sdk-v2/blob/develop/tdl_sdk/tool/yolo_export/yolov8_export.py
model_transform.py \
--model_name yolov8n \
--model_def best.onnx \
--input_shapes [[1,3,640,640]] \
--mean 0.0,0.0,0.0 \
--scale 0.0039216,0.0039216,0.0039216 \
--keep_aspect_ratio \
--pixel_format rgb \
--mlir yolov8n.mlir
fotos na pasta BUGGIO estavam 640x640
run_calibration.py yolov8n.mlir \
--dataset ../../BUGGIO \
--input_num 100 \
-o yolov8n_cali_table
model_deploy.py \
--mlir yolov8n.mlir \
--quant_input --quant_output \
--quantize INT8 \
--calibration_table yolov8n_cali_table \
--processor cv181x \
--model yolov8n_cv181x_int8_sym.cvimodel
python tdl sdk sophgo example
tdl_sophgo.py
python tdl_sophgo.py /root/cv181x/yolov8n_cv181x_int8_sym_cv181x.cvimodel Barbie_5-4_jpg.rf.64feb144416c82dc7c58b335d7143774.jpg
import sys
import os
from tdl import nn, image
import cv2
import numpy as np
if __name__ == "__main__":
if len(sys.argv) != 3:
print("Usage: python sample_fd.py <model_path> <image_path>")
sys.exit(1)
model_path = sys.argv[1]
img_path = sys.argv[2]
face_detector = nn.get_model(nn.ModelType.YOLOV8, model_path)
img = image.read(img_path)
# img = cv2.imread(img_path)
bboxes = face_detector.inference(img)
print(bboxes)
#https://github.com/sophgo/tdl_sdk/tree/master
python tdl sdk milkv-duo S example
sample_img_object_detection.py
python sample_img_object_detection.py YOLOV8 /root/cv181x/yolov8n_cv181x_int8_sym_cv181x.cvimodel /root/Bauer_9-4_jpg.rf.1ee8c79f82e5c4ed6b2ba3b7d5340d2c.jpg
import sys
import os
from tdl import nn, image
import cv2
import numpy as np
def visualize_objects(img_path, bboxes, save_path="object_detection.jpg"):
"""å¯è§†åŒ–ç›®æ ‡æ£€æµ‹ç»“æžœ"""
img = cv2.imread(img_path)
print(f"检测到 {len(bboxes)} ä¸ªç›®æ ‡")
for i, obj in enumerate(bboxes):
x1, y1, x2, y2 = map(int, [obj['x1'], obj['y1'], obj['x2'], obj['y2']])
class_id = obj['class_id']
score = obj['score']
class_name = obj.get('class_name', f'class_{class_id}')
cv2.rectangle(img, (x1, y1), (x2, y2), (0, 0, 255), 2)
label = f"{class_id}:{score:.2f}"
center_x = (x1 + x2) // 2
center_y = (y1 + y2) // 2
cv2.putText(img, label, (center_x, center_y),
cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 0, 255), 1)
cv2.imwrite(save_path, img)
print(f"ä¿å˜å›¾åƒåˆ°: {save_path}")
if __name__ == "__main__":
if len(sys.argv) < 4 or len(sys.argv) > 5:
print("Usage: python3 sample_img_object_detection.py <model_id_name> <model_dir> <image_path> [threshold]")
# å°šæœªåŠ å…¥å¯¹äºŽä¸æ˜¯æ£€æµ‹æ¨¡åž‹çš„处ç†
sys.exit(1)
model_id_name = sys.argv[1]
model_dir = sys.argv[2]
image_path = sys.argv[3]
threshold = float(sys.argv[4]) if len(sys.argv) == 5 else 0.5
if not os.path.exists(image_path):
print(f"图åƒæ–‡ä»¶ä¸å˜åœ¨: {image_path}")
sys.exit(1)
model_type = getattr(nn.ModelType, model_id_name)
model = nn.get_model(model_type, model_dir, device_id=0)
# 读å–图åƒ
img = image.read(image_path)
# 执行推ç†
outdatas = model.inference(img)
expected_keys = {"class_id", "class_name", "score", "x1", "y1", "x2", "y2"}
is_detection = (
isinstance(outdatas, list) and
isinstance(outdatas[0], dict) and
set(outdatas[0].keys()) == expected_keys
)
if not is_detection:
print("当å‰æ¨¡åž‹ä¸æ˜¯ç›®æ ‡æ£€æµ‹æ¨¡åž‹ï¼Œè¾“出内容:")
print(outdatas)
sys.exit(1)
print(f"out_datas.size: {len(outdatas)}")
for i, obj in enumerate(outdatas):
print(f"obj_meta_index: {i} "
f"class: {obj['class_id']} "
f"score: {obj['score']:.2f} "
f"bbox: {obj['x1']:.2f} {obj['y1']:.2f} {obj['x2']:.2f} {obj['y2']:.2f}")
visualize_objects(image_path, outdatas)
# input: python3 sample_img_object_detection.py <model_id_name> <model_dir> <image_path> [threshold]
# output: obj_meta_index: <index> class: <class_id> score: <score_value> bbox: <x1> <y1> <x2> <y2>
utilizando Script completo
./pt_to_cvimodel_tdl_sdk.sh
python yolov8_export.py
python export_tdl_sdk.py --dataset ../../BUGGIO --test_input ../../BUGGIO/Ades_2-3_jpg.rf.de3d17a6dcc748c6642882198a1c1c76.jpg best.onnx
!!!!!!!!!!!!!!!!!!!!!!!! solucao recamera !!!!!!!!!!!!!!!!!!!!!!!
em
https://colab.research.google.com/github/roboflow-ai/notebooks/blob/main/notebooks/train-yolo11-object-detection-on-custom-dataset.ipynb#scrollTo=tdSMcABDNKW-yolo11s
!pip install ultralytics==8.2.103 -q
faça o upgrade
pip install --upgrade --force-reinstall ultralytics
copie o zip do BUGGIO
!unzip /context/buggio.v1i.yolov11.zip
treine
!yolo task=detect mode=train model=yolo11n.pt data=data.yaml epochs=200 imgsz=640
./pt_to_cvimodel_recamera.sh
yolo export model=best.pt format=onnx imgsz=640,640
python export_recamera.py --output_names "/model.23/cv2.0/cv2.0.2/Conv_output_0,/model.23/cv3.0/cv3.0.2/Conv_output_0,/model.23/cv2.1/cv2.1.2/Conv_output_0,/model.23/cv3.1/cv3.1.2/Conv_output_0,/model.23/cv2.2/cv2.2.2/Conv_output_0,/model.23/cv3.2/cv3.2.2/Conv_output_0" --dataset ../../BUGGIO --test_input ../../BUGGIO/Barbie_7-10_jpg.rf.502fbff248ff3b2336a9e60317de843b.jpg best.onnx --quantize INT8
testar cvimodel no recamera
model_transform --model_name best --model_def ./best.onnx --input_shapes '[[1,3,640,640]]' --mean 0.0,0.0,0.0 --scale 0.0039216,0.0039216,0.0039216 --keep_aspect_ratio --pixel_format rgb --output_names /model.23/cv2.0/cv2.0.2/Conv_output_0,/model.23/cv3.0/cv3.0.2/Conv_output_0,/model.23/cv2.1/cv2.1.2/Conv_output_0,/model.23/cv3.1/cv3.1.2/Conv_output_0,/model.23/cv2.2/cv2.2.2/Conv_output_0,/model.23/cv3.2/cv3.2.2/Conv_output_0 --test_input ../../BUGGIO/Ades_2-4_jpg.rf.4de8403c125c5d16b435a839a3a93780.jpg --test_result best_top_outputs.npz --mlir best.mlir
run_calibration best.mlir --dataset ../../BUGGIO --input_num 200 -o best_calib_table
model_deploy --mlir best.mlir --quantize INT8 --quant_input --processor cv181x --calibration_table best_calib_table --test_input ../../BUGGIO/Ades_2-4_jpg.rf.4de8403c125c5d16b435a839a3a93780.jpg --test_reference best_top_outputs.npz --customization_format RGB_PACKED --fuse_preprocess --aligned_input --model best_cv181x_int8.cvimodel
model_transform \
--model_name yolo11n \
--model_def best.onnx \
--input_shapes "[[1,3,640,640]]" \
--mean "0.0,0.0,0.0" \
--scale "0.0039216,0.0039216,0.0039216" \
--keep_aspect_ratio \
--pixel_format rgb \
--output_names "/model.23/cv2.0/cv2.0.2/Conv_output_0,/model.23/cv3.0/cv3.0.2/Conv_output_0,/model.23/cv2.1/cv2.1.2/Conv_output_0,/model.23/cv3.1/cv3.1.2/Conv_output_0,/model.23/cv2.2/cv2.2.2/Conv_output_0,/model.23/cv3.2/cv3.2.2/Conv_output_0" \
--test_input ../../BUGGIO/Ades_2-3_jpg.rf.de3d17a6dcc748c6642882198a1c1c76.jpg \
--test_result yolo11n_top_outputs.npz \
--mlir yolo11n.mlir
run_calibration \
yolo11n.mlir \
--dataset ../../BUGGIO \
--input_num 100 \
-o yolo11n_calib_table
model_deploy \
--mlir yolo11n.mlir \
--quantize INT8 \
--quant_input \
--processor cv181x \
--calibration_table yolo11n_calib_table \
--test_input ../../BUGGIO/Ades_2-3_jpg.rf.de3d17a6dcc748c6642882198a1c1c76.jpg \
--test_reference yolo11n_top_outputs.npz \
--customization_format RGB_PACKED \
--fuse_preprocess \
--aligned_input \
--model yolo11n_1684x_int8_sym.cvimodel
=======car counting
https://github.com/Seeed-Studio/sscma-example-sg200x/tree/main/solutions/sscma-model/main
yolo export model=best.pt format=onnx opset=14
python export_recamera.py --output_names "/model.23/cv2.0/cv2.0.2/Conv_output_0,/model.23/cv3.0/cv3.0.2/Conv_output_0,/model.23/cv2.1/cv2.1.2/Conv_output_0,/model.23/cv3.1/cv3.1.2/Conv_output_0,/model.23/cv2.2/cv2.2.2/Conv_output_0,/model.23/cv3.2/cv3.2.2/Conv_output_0" --dataset ../../CARS --test_input ../../CARS/DOH_3-video-converter_com-_mp4-26_jpg.rf.a6a631199f4152b1ab619e3e3cf6e8ee.jpg best.onnx --quantize INT8
model_transform \
--model_name yolo11n \
--model_def best.onnx \
--input_shapes "[[1,3,640,640]]" \
--mean "0.0,0.0,0.0" \
--scale "0.0039216,0.0039216,0.0039216" \
--keep_aspect_ratio \
--pixel_format rgb \
--output_names "/model.23/cv2.0/cv2.0.2/Conv_output_0,/model.23/cv3.0/cv3.0.2/Conv_output_0,/model.23/cv2.1/cv2.1.2/Conv_output_0,/model.23/cv3.1/cv3.1.2/Conv_output_0,/model.23/cv2.2/cv2.2.2/Conv_output_0,/model.23/cv3.2/cv3.2.2/Conv_output_0" \
--test_input ../../CARS/DOH_3-video-converter_com-_mp4-26_jpg.rf.a6a631199f4152b1ab619e3e3cf6e8ee.jpg \
--test_result yolo11n_top_outputs.npz \
--mlir yolo11n.mlir
run_calibration \
yolo11n.mlir \
--dataset ../../CARS \
--input_num 100 \
-o yolo11n_calib_table
model_deploy \
--mlir yolo11n.mlir \
--quantize INT8 \
--quant_input \
--processor cv181x \
--calibration_table yolo11n_calib_table \
--test_input ../../CARS/DOH_3-video-converter_com-_mp4-26_jpg.rf.a6a631199f4152b1ab619e3e3cf6e8ee.jpg \
--test_reference yolo11n_top_outputs.npz \
--customization_format RGB_PACKED \
--fuse_preprocess \
--aligned_input \
--model yolo11n_1684x_int8_sym.cvimodel
yolo26n
model_transform \
--model_name yolo26n \
--model_def best_26.onnx \
--input_shapes "[[1,3,640,640]]" \
--mean "0.0,0.0,0.0" \
--scale "0.0039216,0.0039216,0.0039216" \
--keep_aspect_ratio \
--pixel_format rgb \
--output_names "/model.23/cv2.0/cv2.0.2/Conv_output_0,/model.23/cv3.0/cv3.0.2/Conv_output_0,/model.23/cv2.1/cv2.1.2/Conv_output_0,/model.23/cv3.1/cv3.1.2/Conv_output_0,/model.23/cv2.2/cv2.2.2/Conv_output_0,/model.23/cv3.2/cv3.2.2/Conv_output_0" \
--test_input ../../BUGGIO/Ades_2-4_jpg.rf.4de8403c125c5d16b435a839a3a93780.jpg \
--test_result yolo26n_top_outputs.npz \
--mlir yolo26n.mlir
run_calibration \
yolo26n.mlir \
--dataset ../../BUGGIO \
--input_num 100 \
-o yolo26n_calib_table
model_deploy \
--mlir yolo26n.mlir \
--quantize INT8 \
--quant_input \
--processor cv181x \
--calibration_table yolo26n_calib_table \
--test_input ../../BUGGIO/Ades_2-4_jpg.rf.4de8403c125c5d16b435a839a3a93780.jpg \
--test_reference yolo26n_top_outputs.npz \
--customization_format RGB_PACKED \
--fuse_preprocess \
--aligned_input \
--model yolo26n_1684x_int8_sym.cvimodel
https://github.com/ultralytics/ultralytics/blob/ee2ac9e43491e5ca61a158fb3a42e621a6710ee1/docs/en/integrations/seeedstudio-recamera.md?plain=1#L62
https://github.com/Seeed-Studio/SSCMA-Micro
https://docs.ultralytics.com/modes/predict/#key-features-of-predict-mode
https://github.com/Seeed-Studio/reCamera-OS/tree/sg200x-reCamera/external/br2-external
segunda-feira, 19 de janeiro de 2026
domingo, 12 de outubro de 2025
emu8086 - count
/* Main.c file generated by New Project wizard
*
* Created: sáb out 11 2025
* Processor: 8086
* Compiler: Digital Mars C
*
* Before starting simulation set Internal Memory Size
* in the 8086 model properties to 0x10000
*/
// robot base i/o port:
#define r_port 9
unsigned int count = 0;
void Robot(void)
{
asm {
//===================================
mov ax,0
mov dx,199
out dx,ax
eternal_loop:
cmp count,5
je Happy
// wait until robot
// is ready:
call wait_robot
// examine the area
// in front of the robot:
mov al, 4
out r_port, al
call wait_exam
// get result from
// data register:
in al, r_port + 1
// nothing found?
cmp al, 0
je cont // - yes, so continue.
// wall?
cmp al, 255
je cont // - yes, so continue.
// switched-on lamp?
cmp al, 7
jne lamp_off // - no, so skip.
// - yes, so switch it off,
// and turn:
//call switch_off_lamp
jmp cont // continue
lamp_off: nop
// if gets here, then we have
// switched-off lamp, because
// all other situations checked
// already:
call switch_on_lamp
cont:
call random_turn
call wait_robot
// try to step forward:
mov al, 1
out r_port, al
call wait_robot
// try to step forward again:
mov al, 1
out r_port, al
jmp eternal_loop // go again!
//===================================
// this procedure does not
// return until robot is ready
// to receive next command:
wait_robot:
// check if robot busy:
busy: in al, r_port+2
test al, 0b00000010
jnz busy // busy, so wait.
ret
//===================================
// this procedure does not
// return until robot completes
// the examination:
wait_exam:
// check if has new data:
busy2: in al, r_port+2
test al, 0b00000001
jz busy2 // no new data, so wait.
ret
//===================================
// switch off the lamp:
switch_off_lamp:
mov al, 6
out r_port, al
ret
//===================================
// switch on the lamp:
switch_on_lamp:
syncronize:
mov al, 5
out r_port, al
// wait until robot
// is ready:
call wait_robot
// examine the area
// in front of the robot:
mov al, 4
out r_port, al
call wait_exam
// get result from
// data register:
in al, r_port + 1
cmp al,8
je syncronize
cmp al,255
je syncronize
inc count
mov ax,count
mov dx,199
out dx,ax
ret
//===================================
// generates a random turn using
// system timer:
random_turn:
// get number of clock
// ticks since midnight
// in cx:dx
mov ah, 0
int 1ah
// randomize using xor:
xor dh, dl
xor ch, cl
xor ch, dh
test ch, 2
jz no_turn
test ch, 1
jnz turn_right
// turn left:
mov al, 2
out r_port, al
// exit from procedure:
ret
turn_right:
mov al, 3
out r_port, al
no_turn:
ret
//===================================
Happy:
mov al, 3
out r_port, al
call wait_robot
// try to step forward:
mov al, 1
out r_port, al
call wait_robot
jmp Happy
}
}
void main(void)
{
// Write your code here
Robot();
while (1)
{
}
}
20BYJ46

STEP MOTOR 20BYJ46
VEMELHO (12V)
AZUL (D1)
ROSA (D2)
AMARELO (D3)
LARANJA (D4)


REF: STM32驱动小型4相步进电机(ULN2003+20BYJ46)-CSDN博客
28BYJ-48 Stepper Motor Pinout Wiring, Specifications, Uses Guide & Datasheet
domingo, 5 de outubro de 2025
PT TO CVIMODEL


Geração do .pt
Entre em
E nele, basicamente deves pegar o ZIP (yolov11) gerado no ROBOFLOW, descompactar, instalar o ULTRALYTICS (yolo)%pip install "ultralytics<=8.3.40" supervision roboflow# prevent ultralytics from tracking your activity!yolo settings sync=Falseimport ultralyticsultralytics.checks()..após isto executar o Script!yolo task=detect mode=train model=yolo11n.pt data=data.yaml epochs=200 imgsz=640
Salve o .pt gerado
Instale o TPU MLIR e ULTRALYTICS em seu PC
"Se já instalado
docket psdocker exec -it xxxxxxx /bin/bash"
docker run --privileged --name recamera -v /workspace -it sophgo/tpuc_dev:v3.1
on /workspace
sudo apt-get update
sudo apt-get upgrade
pip install tpu_mlir[all]==1.7
git clone https://github.com/sophgo/tpu-mlir.git
cd tpu-mlir
source ./envsetup.sh
./build.sh
mkdir model_yolo11n && cd model_yolo11n
cp -rf ${REGRESSION_PATH}/dataset/COCO2017 .
cp -rf ${REGRESSION_PATH}/image .
mkdir Workspace && cd Workspace
pip install ultralytics
(crie em /dataset/ o nome de uma pasta com as imagens treinadas)
(dentro de /image/copie uma imagem das imagens treinadas)
### git clone https://github.com/Seeed-Studio/sscma-example-sg200x.git
### cd sscma-example-sg200x/scripts
### (copy into this folder the best.onnx)### dentro de /workspace/tpu-mlir/model_yolo11n/sscma-example-sg200x/scripts
### python export.py --output_names "/model.23/cv2.0/cv2.0.2/Conv_output_0,/model.23/cv3.0/cv3.0.2/Conv_output_0,/model.23/cv2.1/cv2.1.2/Conv_output_0,/model.23/cv3.1/cv3.1.2/Conv_output_0,/model.23/cv2.2/cv2.2.2/Conv_output_0,/model.23/cv3.2/cv3.2.2/Conv_output_0" --dataset ../../../../tpu-mlir/regression/dataset/BUGGIO --test_input ../../../../tpu-mlir/regression/image/Ades_2-4_jpg.rf.4de8403c125c5d16b435a839a3a93780.jpg best.onnx
dentro do /workspace/tpu-mlir/model_yolo11n/Workspace copie o best.pt (gerado no Colab)
execute
yolo export model=best.pt format=onnx imgsz=640,640
será gerado um best.onnx
execute(dentro de /workspace/tpu-mlir/model_yolo11n/Workspace)
model_transform \
--model_name yolo11n \
--model_def best.onnx \
--input_shapes "[[1,3,640,640]]" \
--mean "0.0,0.0,0.0" \
--scale "0.0039216,0.0039216,0.0039216" \
--keep_aspect_ratio \
--pixel_format rgb \
--output_names "/model.23/cv2.0/cv2.0.2/Conv_output_0,/model.23/cv3.0/cv3.0.2/Conv_output_0,/model.23/cv2.1/cv2.1.2/Conv_output_0,/model.23/cv3.1/cv3.1.2/Conv_output_0,/model.23/cv2.2/cv2.2.2/Conv_output_0,/model.23/cv3.2/cv3.2.2/Conv_output_0" \
--test_input ../../../tpu-mlir/regression/image/Ades_2-4_jpg.rf.4de8403c125c5d16b435a839a3a93780.jpg \
--test_result yolo11n_top_outputs.npz \
--mlir yolo11n.mlir
execute
run_calibration \
yolo11n.mlir \
--dataset ../BUGGIO \
--input_num 100 \
-o yolo11n_calib_table
execute
model_deploy \
--mlir yolo11n.mlir \
--quantize INT8 \
--quant_input \
--processor cv181x \
--calibration_table yolo11n_calib_table \
--test_input ../../../tpu-mlir/regression/image/Ades_2-4_jpg.rf.4de8403c125c5d16b435a839a3a93780.jpg \
--test_reference yolo11n_top_outputs.npz \
--customization_format RGB_PACKED \
--fuse_preprocess \
--aligned_input \
--model yolo11n_1684x_int8_sym.cvimodel
cvimodel se encontra em
/workspace/tpu-mlir/model_yolo11n/Workspace
\\wsl.localhost\docker-desktop\mnt\docker-desktop-disk\data\docker\volumes\8bd5aab9644ef6f95e9275c42306a33a7313a58d86c9a1a7ab20e4a24f5649aa\_data\tpu-mlir\model_yolo11n\Workspace
### o script do RECAMERA
 REF:Model Conversion Guide | Seeed Studio Wiki
REF:Model Conversion Guide | Seeed Studio Wiki
Roboflow: Computer vision tools for developers and enterprises
sscma-example-sg200x/scripts/export.py at c027ed4ea14564b69530a9958150953182443126 · Seeed-Studio/sscma-example-sg200x
Monkey CVI model · Issue #37 · Seeed-Studio/reCamera-OS
Sobre a SMARTCORE
A SMARTCORE FORNECE CHIPS E MÓDULOS PARA IOT, COMUNICAÇÃO WIRELESS, BIOMETRIA, CONECTIVIDADE, RASTREAMENTO E AUTOMAÇÃO. NOSSO PORTFÓLIO INCLUI MODEM 2G/3G/4G/NB-IOT, SATELITAL, MÓDULOS WIFI, BLUETOOTH, GPS, SIGFOX, LORA, LEITOR DE CARTÃO, LEITOR QR CCODE, MECANISMO DE IMPRESSÃO, MINI-BOARD PC, ANTENA, PIGTAIL, BATERIA, REPETIDOR GPS E SENSORES
Entre em
E nele, basicamente deves pegar o ZIP (yolov11) gerado no ROBOFLOW, descompactar, instalar o ULTRALYTICS (yolo)
%pip install "ultralytics<=8.3.40" supervision roboflow
# prevent ultralytics from tracking your activity
!yolo settings sync=False
import ultralytics
ultralytics.checks()
..após isto executar o Script
!yolo task=detect mode=train model=yolo11n.pt data=data.yaml epochs=200 imgsz=640
Salve o .pt gerado
Instale o TPU MLIR e ULTRALYTICS em seu PC
"Se já instalado
docket ps
docker exec -it xxxxxxx /bin/bash"
docker run --privileged --name recamera -v /workspace -it sophgo/tpuc_dev:v3.1
on /workspace
sudo apt-get update
sudo apt-get upgrade
pip install tpu_mlir[all]==1.7
git clone https://github.com/sophgo/tpu-mlir.git
cd tpu-mlir
source ./envsetup.sh
./build.sh
mkdir model_yolo11n && cd model_yolo11n
cp -rf ${REGRESSION_PATH}/dataset/COCO2017 .
cp -rf ${REGRESSION_PATH}/image .
mkdir Workspace && cd Workspace
pip install ultralytics
(crie em /dataset/ o nome de uma pasta com as imagens treinadas)
(dentro de /image/copie uma imagem das imagens treinadas)
### git clone https://github.com/Seeed-Studio/sscma-example-sg200x.git
### cd sscma-example-sg200x/scripts
### (copy into this folder the best.onnx)
### dentro de /workspace/tpu-mlir/model_yolo11n/sscma-example-sg200x/scripts
### python export.py --output_names "/model.23/cv2.0/cv2.0.2/Conv_output_0,/model.23/cv3.0/cv3.0.2/Conv_output_0,/model.23/cv2.1/cv2.1.2/Conv_output_0,/model.23/cv3.1/cv3.1.2/Conv_output_0,/model.23/cv2.2/cv2.2.2/Conv_output_0,/model.23/cv3.2/cv3.2.2/Conv_output_0" --dataset ../../../../tpu-mlir/regression/dataset/BUGGIO --test_input ../../../../tpu-mlir/regression/image/Ades_2-4_jpg.rf.4de8403c125c5d16b435a839a3a93780.jpg best.onnx
dentro do /workspace/tpu-mlir/model_yolo11n/Workspace copie o best.pt (gerado no Colab)
execute
yolo export model=best.pt format=onnx imgsz=640,640
será gerado um best.onnx
execute
(dentro de /workspace/tpu-mlir/model_yolo11n/Workspace)
model_transform \
--model_name yolo11n \
--model_def best.onnx \
--input_shapes "[[1,3,640,640]]" \
--mean "0.0,0.0,0.0" \
--scale "0.0039216,0.0039216,0.0039216" \
--keep_aspect_ratio \
--pixel_format rgb \
--output_names "/model.23/cv2.0/cv2.0.2/Conv_output_0,/model.23/cv3.0/cv3.0.2/Conv_output_0,/model.23/cv2.1/cv2.1.2/Conv_output_0,/model.23/cv3.1/cv3.1.2/Conv_output_0,/model.23/cv2.2/cv2.2.2/Conv_output_0,/model.23/cv3.2/cv3.2.2/Conv_output_0" \
--test_input ../../../tpu-mlir/regression/image/Ades_2-4_jpg.rf.4de8403c125c5d16b435a839a3a93780.jpg \
--test_result yolo11n_top_outputs.npz \
--mlir yolo11n.mlir
execute
run_calibration \
yolo11n.mlir \
--dataset ../BUGGIO \
--input_num 100 \
-o yolo11n_calib_table
execute
model_deploy \
--mlir yolo11n.mlir \
--quantize INT8 \
--quant_input \
--processor cv181x \
--calibration_table yolo11n_calib_table \
--test_input ../../../tpu-mlir/regression/image/Ades_2-4_jpg.rf.4de8403c125c5d16b435a839a3a93780.jpg \
--test_reference yolo11n_top_outputs.npz \
--customization_format RGB_PACKED \
--fuse_preprocess \
--aligned_input \
--model yolo11n_1684x_int8_sym.cvimodel
cvimodel se encontra em
/workspace/tpu-mlir/model_yolo11n/Workspace
\\wsl.localhost\docker-desktop\mnt\docker-desktop-disk\data\docker\volumes\8bd5aab9644ef6f95e9275c42306a33a7313a58d86c9a1a7ab20e4a24f5649aa\_data\tpu-mlir\model_yolo11n\Workspace
### o script do RECAMERA

REF:
Model Conversion Guide | Seeed Studio Wiki
Roboflow: Computer vision tools for developers and enterprises
sscma-example-sg200x/scripts/export.py at c027ed4ea14564b69530a9958150953182443126 · Seeed-Studio/sscma-example-sg200x
Monkey CVI model · Issue #37 · Seeed-Studio/reCamera-OS
Roboflow: Computer vision tools for developers and enterprises
sscma-example-sg200x/scripts/export.py at c027ed4ea14564b69530a9958150953182443126 · Seeed-Studio/sscma-example-sg200x
Monkey CVI model · Issue #37 · Seeed-Studio/reCamera-OS
Sobre a SMARTCORE
A SMARTCORE FORNECE CHIPS E MÓDULOS PARA IOT, COMUNICAÇÃO WIRELESS, BIOMETRIA, CONECTIVIDADE, RASTREAMENTO E AUTOMAÇÃO. NOSSO PORTFÓLIO INCLUI MODEM 2G/3G/4G/NB-IOT, SATELITAL, MÓDULOS WIFI, BLUETOOTH, GPS, SIGFOX, LORA, LEITOR DE CARTÃO, LEITOR QR CCODE, MECANISMO DE IMPRESSÃO, MINI-BOARD PC, ANTENA, PIGTAIL, BATERIA, REPETIDOR GPS E SENSORES
A SMARTCORE FORNECE CHIPS E MÓDULOS PARA IOT, COMUNICAÇÃO WIRELESS, BIOMETRIA, CONECTIVIDADE, RASTREAMENTO E AUTOMAÇÃO. NOSSO PORTFÓLIO INCLUI MODEM 2G/3G/4G/NB-IOT, SATELITAL, MÓDULOS WIFI, BLUETOOTH, GPS, SIGFOX, LORA, LEITOR DE CARTÃO, LEITOR QR CCODE, MECANISMO DE IMPRESSÃO, MINI-BOARD PC, ANTENA, PIGTAIL, BATERIA, REPETIDOR GPS E SENSORES
segunda-feira, 2 de junho de 2025
MILK-V DUO S - OPEN SDK V2 NO MILK-V DUO S - IMAGENS PARA O FURBOT
Introdução

A detecção de objetos é um campo fascinante que ganhou muita atenção nos últimos anos devido à sua ampla gama de aplicações em áreas como carros autônomos, sistemas de segurança e assistência médica. YOLO11 (You Only Look Once versão 11) é um modelo de detecção de objetos de última geração que se tornou cada vez mais popular devido à sua alta precisão e velocidade de processamento rápida. Neste guia para iniciantes, exploraremos as etapas envolvidas no treinamento de um modelo YOLOv"11" do zero, incluindo preparação de dados, configuração do modelo e treinamento. Seja você um iniciante em aprendizado profundo ou um praticante experiente, este guia fornecerá uma base sólida para treinar seu próprio modelo YOLO11 e explorar o campo emocionante da detecção de objetos.
Sobre o Projeto Furbot
Com a introdução da Base Nacional Comum Curricular (BNCC), várias discussões ocorreram para identificar qual a melhor maneira de efetivar a inclusão dos fundamentos da Ciência da Computação, especificamente relacionados ao Pensamento Computacional (PC), na educação básica. Durante os últimos doze anos, uma tecnologia para o desenvolvimento de habilidades de PC em cursos de graduação foi desenvolvida e aprimorada, chamada Furbot, que há quatro anos se tornou um jogo e foi aplicada com sucesso no Ensino Fundamental I em escolas públicas estaduais da região de Blumenau. Assim, o jogo Furbot, desenvolvido em Unity 2D, tem como objetivo fazer com que o jogador saia de um ponto de origem e chegue a um ponto de destino, guiando um robô por um caminho e desviando de obstáculos usando comandos de programação.
Neste exemplo, pretende-se substituir as Flechas acimas por uma Flechas especializadas e já disponíveis no mundo RoboFlow. Tentou-se treinar as acima, mas o fundo branco de cada uma delas foi uma preocupação.
Atualmente as mesmas são capturadas por uma câmera do ESP32CAM e enviadas para o serviços da AMAZON para reconhecimento, pretende-se substituir o ESP32CAM e o serviço da AMAZON por um MILK-V com Rede Neural treinada e uma câmara USB acoplada a ele.
O Furbot sofreu mais transformações (não especificadas no HackAday), entre elas, uma aplicação python rodando em um PC o qual captura uma imagem via Wifi da câmera do ESP32CAM e detecta as bordas do tapete. Pretende-se então portar também para o Milk-v Duo S a aplicação python.

OpenCV rodando no MILK-V Duo S
import cv2
import requests
import numpy as np
import time
from enum import Enum
import threading
# Replace the below URL with your ESP32-CAM video stream URL
ip = '192.168.1.8'
stream_url = 'http://'+ ip +':82/stream'
post_url = 'http://'+ ip +':81/comando'
_grupos = []
_lastGrupos = []
_lastId = 1
_threshold = 50
up = False
down = False
left = False
right = False
passouPrimeiraLinha = False
primeiraPassada = True
class Comandos(Enum):
UP = 'UP'
DOWN = 'DOWN'
LEFT = 'LEFT'
RIGHT = 'RIGHT'
DLEFT = 'DLEFT'
DRIGHT = 'DRIGHT'
STOP = 'STOP'
CORRECT = 'CORRECT'
def calcular_media_dos_y_do_grupo(grupo):
# Inicialize uma lista para armazenar as medias dos valores de y de cada linha
medias_y = []
# Itere sobre as linhas no grupo
for linha in grupo[4]: # grupo[4] contem a lista de linhas
x1, y1, x2, y2, _ = linha # Ignorando "group" porque nao precisamos dela aqui
# Calcule a media dos valores de y da linha atual e adicione a lista
media_y_linha = (y1 + y2) / 2
medias_y.append(media_y_linha)
# Calcule a media das medias dos valores de y das linhas
media_geral_y = sum(medias_y) / len(medias_y)
grupo[2] = media_geral_y
return media_geral_y
def calcular_media_dos_x_do_grupo(grupo):
# Inicialize uma lista para armazenar as medias dos valores de x de cada linha
medias_x = []
# Itere sobre as linhas no grupo
for linha in grupo[4]: # grupo[4] contem a lista de linhas
x1, y1, x2, y2, _ = linha # Ignorando "group" porque nao precisamos dela aqui
# Calcule a media dos valores de x da linha atual e adicione a lista
media_x_linha = (x1 + x2) / 2
medias_x.append(media_x_linha)
# Calcule a media das medias dos valores de x das linhas
media_geral_x = sum(medias_x) / len(medias_x)
grupo[2] = media_geral_x
return media_geral_x
def calcular_media_dos_angulos_do_grupo(grupo, target_x=420, target_y=250):
# Inicialize variaveis para armazenar a menor distancia e a linha correspondente
menor_distancia = float('inf')
linha_mais_proxima = None
# Itere sobre as linhas no grupo
for linha in grupo[4]: # grupo[4] contem a lista de linhas
x1, y1, x2, y2, _ = linha # Ignorando "group" porque nao precisamos dela aqui
# Calcule o ponto medio da linha
ponto_medio_x = (x1 + x2) / 2
ponto_medio_y = (y1 + y2) / 2
# Calcule a distancia euclidiana do ponto medio ao ponto alvo
distancia = ((ponto_medio_x - target_x) ** 2 + (ponto_medio_y - target_y) ** 2) ** 0.5
# Se a distancia atual e menor que a menor distancia registrada, atualize a menor distancia e a linha correspondente
if distancia < menor_distancia:
menor_distancia = distancia
linha_mais_proxima = linha
x1, y1, x2, y2, _ = linha_mais_proxima
angle = calculate_angle(x1, y1, x2, y2)
grupo[3] = angle
return angle
def calculate_angle(x1, y1, x2, y2):
"""
Calculate the angle (in degrees) of a line segment with endpoints (x1, y1) and (x2, y2).
"""
angle_radians = np.arctan2(y2 - y1, x2 - x1)
angle_degrees = np.degrees(angle_radians)
return angle_degrees
def color_by_group(group):
if group == "horizontal":
return (0, 255, 0)
return (0, 0, 255)
def get_group_by_id(group_id):
for group in _grupos:
if group[0] == group_id:
return group
return None
def remove_from_last_group_by_id(group_id):
global _lastGrupos # Declare _grupos as global so that it can be modified within the function
_lastGrupos = [group for group in _lastGrupos if group[0] != group_id]
def agrupaLinha(line):
global _lastId
x1, y1, x2, y2, group = line
if(group == "horizontal"):
mediaLinha = (y1+y2)/2
angle = calculate_angle(x1, y1, x2, y2)
if mediaLinha > 330:
if get_group_by_id(-1) is None:
_grupos.append([-1, group, mediaLinha, angle, [line]])
else:
grupoFora = get_group_by_id(-1)
id, direcao, media, angle, linhas = grupoFora
linhas.append(line)
calcular_media_dos_y_do_grupo(grupoFora)
else:
for i in range(_lastGrupos.__len__()):
idLastGrupo, direcaoLastGrupo, mediaLastGrupo, angleLastGrupo, linhasLastGrupo = _lastGrupos[i]
if direcaoLastGrupo == "horizontal":
if (mediaLastGrupo - _threshold < mediaLinha < mediaLastGrupo + _threshold):
for i in range(_grupos.__len__()):
id, direcao, media, angle, linhas = _grupos[i]
if id == idLastGrupo:
linhas.append(line)
_grupos[i] = [id, direcao, media, angle, linhas]
calcular_media_dos_y_do_grupo(_grupos[i])
calcular_media_dos_angulos_do_grupo(_grupos[i])
return
_grupos.append([idLastGrupo, group, mediaLinha, angle, [line]])
return
for i in range(_grupos.__len__()):
id, direcao, media, angle, linhas = _grupos[i]
if direcao == "horizontal":
if(media - _threshold < mediaLinha < media + _threshold):
linhas.append(line)
_grupos[i] = [id, direcao, media, angle, linhas]
calcular_media_dos_y_do_grupo(_grupos[i])
calcular_media_dos_angulos_do_grupo(_grupos[i])
return
_grupos.append([_lastId, group, mediaLinha, angle, [line]])
_lastId = _lastId + 1
elif(group == "vertical"):
mediaLinha = (x1 + x2) / 2
angle = calculate_angle(x1, y1, x2, y2)
for i in range(_lastGrupos.__len__()):
idLastGrupo, direcaoLastGrupo, mediaLastGrupo, angleLastGrupo, linhasLastGrupo = _lastGrupos[i]
if direcaoLastGrupo == "vertical":
if (mediaLastGrupo - _threshold < mediaLinha < mediaLastGrupo + _threshold):
for i in range(_grupos.__len__()):
id, direcao, media, angle, linhas = _grupos[i]
if id == idLastGrupo:
linhas.append(line)
_grupos[i] = [id, direcao, media, angle, linhas]
calcular_media_dos_x_do_grupo(_grupos[i])
calcular_media_dos_angulos_do_grupo(_grupos[i])
return
_grupos.append([idLastGrupo, group, mediaLinha, angle, [line]])
return
for i in range(_grupos.__len__()):
id, direcao, media, angle, linhas = _grupos[i]
if direcao == "vertical":
if (media - _threshold < mediaLinha < media + _threshold):
linhas.append(line)
_grupos[i] = [id, direcao, media, angle, linhas]
calcular_media_dos_x_do_grupo(_grupos[i])
calcular_media_dos_angulos_do_grupo(_grupos[i])
return
_grupos.append([_lastId, group, mediaLinha, angle, [line]])
_lastId = _lastId + 1
# Grupo tera: {
# id: 1
# direcao: horizontal|vertical
# media: 50 (media do valor X caso vertical, media do Y caso horizontal)
# linhas: lista das linhas
# }
#
# 1. Passar _grupos para _lastGrupos
# 2. Adicionar linhas atuais no _grupos
# 1- Passar pelos grupos da direcao correta
# 2- Verificar se tem alguma media que esta perto (threshold) do valor medio do Y da linha atual
# 2.1 - Usa os grupos antigos para ter as medias, caso nao tenha um grupo antigo perto da linha atual, cria um grupo
# 3- Adicionar linha no grupo, recalcular media do grupo
#
def any_group_media_greater_than_300():
for group in _grupos:
if group[1] == "horizontal" and group[2] > 250 and group[0] > -1:
return True
return False
def corrigir_angulo(grupo):
angle = grupo[3]
if angle > -1 and angle < 1:
return
if angle < 0:
send_request(Comandos.LEFT, angle)
else:
send_request(Comandos.RIGHT, angle)
def corrigir_meio():
time.sleep(3)
grupoEsquerda = []
grupoDireita = []
for grupo in _grupos:
if grupo[0] > -1 and grupo[1] == "vertical":
diferenca = grupo[2] - 398
if diferenca < 0:
if len(grupoEsquerda) == 0 or abs(diferenca) < abs((grupoEsquerda[2] - 398)):
grupoEsquerda = grupo
else:
if len(grupoDireita) == 0 or diferenca < abs((grupoDireita[2] - 398)):
grupoDireita = grupo
if len(grupoEsquerda) > 0 and len(grupoDireita) > 0:
mediaCorrecao = (grupoEsquerda[2] + grupoDireita[2])/2
diferenca = mediaCorrecao - 398
if abs(diferenca) > 5:
if(diferenca > 0):
send_request(Comandos.DRIGHT, diferenca)
else:
send_request(Comandos.DLEFT, diferenca)
def corrigir_geral(id, direcao, media, angle, linhas):
time.sleep(8)
grupo = [id, direcao, media, angle, linhas]
corrigir_angulo(grupo)
thread = threading.Thread(target=corrigir_meio)
thread.start()
def detect_lines(frame):
global _grupos
_lastGrupos.clear()
if len(_grupos) > 0:
_lastGrupos.extend(_grupos)
_grupos = []
remove_from_last_group_by_id(-1)
# # Convert to grayscale
# gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
# # Apply Gaussian blur
# blur = cv2.GaussianBlur(gray, (5, 5), 0)
# # Apply Canny edge detector
# edges = cv2.Canny(blur, 70, 150, apertureSize=3)
# cv2.imshow('Ee', edges)
#
# # Use HoughLinesP to detect lines
# # These parameters can be adjusted to better detect lines in your specific setting
# lines = cv2.HoughLinesP(edges, 1, np.pi / 180, threshold=100, minLineLength=50, maxLineGap=50)
# Convert to grayscale
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
# Preprocess the image to remove noise
gray = cv2.GaussianBlur(gray, (5, 5), 0)
# Apply adaptive thresholding
thresh = cv2.adaptiveThreshold(gray, 255, cv2.ADAPTIVE_THRESH_GAUSSIAN_C, cv2.THRESH_BINARY_INV, 15, 8)
# cv2.imshow('thresh', thresh)
# Apply Canny edge detector
edges = cv2.Canny(thresh, 50, 150)
# cv2.imshow('edges', edges)
# Use HoughLinesP to detect lines
lines = cv2.HoughLinesP(edges, 1, np.pi / 180, threshold=100, minLineLength=50, maxLineGap=50)
lines_aux = []
if lines is not None:
for line in lines:
x1, y1, x2, y2 = line[0]
angle = calculate_angle(x1, y1, x2, y2)
if (-45 >= angle >= -135) or (45 <= angle <= 135):
group = "vertical"
else:
group = "horizontal"
lines_aux.append([x1, y1, x2, y2, group])
if lines_aux is not None:
for line in lines_aux:
x1, y1, x2, y2, group = line
cv2.line(frame, (x1, y1), (x2, y2), color_by_group(group), 2)
agrupaLinha(line)
# print()
# print("========")
# for grupo in _grupos:
# print("Id: ", grupo[0], " Direcao: ", grupo[1], " Media: ", grupo[2], " angulo: ", grupo[3], " Qntd. linhas: ", len(grupo[4]))
global up
global left
global right
global passouPrimeiraLinha
global primeiraPassada
if up:
if any_group_media_greater_than_300() and primeiraPassada:
passouPrimeiraLinha = False
if not any_group_media_greater_than_300():
passouPrimeiraLinha = True
for grupo in _grupos:
if grupo[0] > -1 and grupo[1] == "horizontal":
if len(grupo[4]) > 1:
if grupo[2] > 250:
if passouPrimeiraLinha:
up = False
send_request(Comandos.STOP)
corrigir_angulo(grupo)
thread = threading.Thread(target=corrigir_meio)
thread.start()
primeiraPassada = False
if left:
for grupo in _grupos:
if grupo[0] > -1 and grupo[1] == "horizontal":
if len(grupo[4]) > 1:
if grupo[2] > 250:
thread = threading.Thread(target=corrigir_geral, args=grupo)
thread.start()
left = False
if right:
for grupo in _grupos:
if grupo[0] > -1 and grupo[1] == "horizontal":
if len(grupo[4]) > 1:
if grupo[2] > 250:
thread = threading.Thread(target=corrigir_geral, args=grupo)
thread.start()
right = False
return frame
process_interval = 0.2 # seconds, process frames every 0.2 seconds or 5 FPS
last_time = 0
cap = cv2.VideoCapture(0)
paused = False # Variable to track pause state
def send_request(comando, valor=0):
print(comando.value)
# print(comando)
response = "";
if valor == 0:
response = requests.post(post_url, data=comando.value)
else:
if comando == Comandos.LEFT or comando == Comandos.RIGHT:
valor = abs(valor)
formatted_float = f"{valor:.3f}"
data = f"{comando.value}_{formatted_float}"
response = requests.post(post_url, data=data)
elif comando == Comandos.DLEFT or comando == Comandos.DRIGHT:
valor = abs(valor)
formatted_float = f"{valor:.3f}"
data = f"{comando.value}_{formatted_float}"
response = requests.post(post_url, data=data)
# print(response)
def start_command(comando):
global up
global down
global left
global right
global passouPrimeiraLinha
global primeiraPassada
if comando == Comandos.UP:
up = True
passouPrimeiraLinha = False
primeiraPassada = True
if comando == Comandos.DOWN:
down = True
if comando == Comandos.LEFT:
left = True
if comando == Comandos.RIGHT:
right = True
if comando == Comandos.CORRECT:
for grupo in _grupos:
if grupo[0] > -1:
if len(grupo[4]) > 1:
if grupo[2] > 250:
corrigir_angulo(grupo)
thread = threading.Thread(target=corrigir_meio(), args=grupo)
thread.start()
return
send_request(comando)
while True:
ret, frame = cap.read()
current_time = time.time()
if current_time - last_time < process_interval:
continue # Skip this iteration of the loop if interval not passed
last_time = current_time
frame_with_lines = detect_lines(frame)
print(frame)
cap.release()
cv2.destroyAllWindows()
Enfim, câmera ESp32CAM, sensores de detecção de tapete e software PC serão todos embarcados no Furbot. Só permanecerá original a placa de controle dos motores.

Versão antiga do FurBot
Treinamento
Para treinar um modelo de detecção de objetos YOLO11, você deve ter um DataSet de imagens anotadas que indiquem a localização dos objetos que você deseja que o modelo detecte. Embora DataSet de código aberto como COCO e Pascal VOC estejam disponíveis, um DataSet personalizado pode ser mais preciso para seu caso de uso específico. Dividir o DataSet em conjuntos de treinamento e validação também é uma etapa crucial para garantir a precisão e a confiabilidade do seu modelo.
Este blog tem como objetivo orientá-lo por todo o processo de treinamento e avaliação do seu próprio modelo YOLO11. Forneceremos uma introdução aos recursos do YOLO11 e discutiremos como anotar e preparar seu DataSet para treinamento. Em seguida, nos aprofundaremos no aspecto importante do treinamento do modelo, fornecendo instruções passo a passo para treinar seu modelo YOLO11 do zero. Por fim, explicaremos como avaliar o desempenho do seu modelo, fornecendo todo o conhecimento necessário para começar a detecção de objetos usando o YOLOv11. Seja você novo na detecção de objetos ou esteja procurando melhorar suas habilidades, este guia abrangente o equipará com as ferramentas necessárias para treinar um modelo de detecção de objetos YOLO11 com confiança.
Introdução
YOLOv11 "é" a versão mais recente e melhor da família YOLO (You Only Look Once) de modelos de detecção de objetos em tempo real. Desenvolvido por Glenn Jocher e a equipe da Ultralytics, o YOLOv11 representa uma revisão completa de seus predecessores e ostenta melhorias significativas em velocidade e precisão. Na verdade, o YOLO11 alcançou resultados de última geração em detecção de objetos em uma variedade de DataSet, incluindo os conhecidos benchmarks COCO e Pascal VOC.
Então o que torna o YOLOv11 tão especial? Sua arquitetura! O YOLO11 alavanca uma nova rede de backbone chamada CSPDarknet, que usa conexões parciais entre estágios para melhorar o fluxo de informações e a reutilização de recursos. Além disso, ele integra técnicas de ponta como Módulos de Atenção Espacial e funções de ativação Swish para aumentar ainda mais a precisão da detecção de objetos. Tudo isso mantendo velocidades de inferência em tempo real de até 140 quadros por segundo em uma única GPU, tornando-o um dos modelos de detecção de objetos mais rápidos e precisos que existem. Se você está procurando desenvolver aplicativos em campos como veículos autônomos, robótica ou sistemas de vigilância, o YOLO11 definitivamente vale uma olhada mais de perto.
DataSet e ferramenta de anotação
A base de qualquer projeto de detecção de objetos bem-sucedido é um DataSet bem curado. O DataSet fornece ao modelo as informações necessárias para reconhecer e localizar objetos com precisão. Portanto, antes de mergulhar no treinamento do modelo, é crucial reunir ou criar um bom DataSet que cubra uma ampla gama de cenários e variações que você prevê que o modelo encontrará no mundo real.
DataSet personalizados desempenham um papel crítico na obtenção de alta precisão e especificidade em tarefas de detecção de objetos. Embora vários DataSet de código aberto estejam disponíveis, como o DataSet COCO e o DataSet EgoHands, criar um DataSet personalizado que atenda ao seu caso de uso específico pode ser mais eficaz. Ferramentas de anotação como LabelImg e Roboflow podem ajudar na criação de tal DataSet No intitulado “Construindo modelos precisos de detecção de objetos com RetinaNet: um guia passo a passo abrangente” , utilizei o LabelImg para anotação de imagem. No entanto, neste blog, demonstrarei como usar o Roboflow, uma ferramenta de anotação poderosa que pode agilizar o processo de preparação do DataSet.
Roboflow é uma plataforma de gerenciamento de dados tudo-em-um projetada para tarefas de visão computacional, como detecção de objetos, classificação de imagens e segmentação. Ela oferece uma gama de ferramentas para anotação de imagens, geração de DataSet e implantação de modelos. Com suas integrações com frameworks populares de aprendizado profundo como TensorFlow e PyTorch, o Roboflow facilita o treinamento de modelos usando seu DataSet personalizado.
Um dos recursos de destaque do Roboflow é sua ferramenta intuitiva de anotação de imagens baseada na web. A ferramenta permite que você rotule imagens com caixas delimitadoras, polígonos e outras formas que indicam a localização de objetos na imagem. Sua interface amigável e eficiência facilitam a rotulagem de grandes DataSet de forma rápida e precisa. Além disso, o Roboflow oferece vários recursos para gerenciar DataSet, incluindo aumento de dados, limpeza de dados e exportação de dados. Ele também fornece opções de pré-processamento, como redimensionamento e normalização, que podem melhorar o desempenho do modelo.
No geral, o Roboflow é uma ferramenta excelente para preparar e gerenciar DataSet personalizados para tarefas de visão computacional. Seus recursos abrangentes e interface amigável o tornam ideal tanto para iniciantes quanto para profissionais experientes. Para começar a usar o Roboflow, crie uma conta e configure um novo espaço de trabalho para começar a criar novos projetos.
Após criar um novo projeto no Roboflow, você pode começar a carregar as imagens que deseja anotar. O processo é simples e fácil de seguir. Você pode carregar imagens diretamente do seu computador ou de serviços de armazenamento em nuvem, como Google Drive ou Dropbox. Depois que as imagens forem carregadas, você pode começar a anotá-las usando as poderosas ferramentas de anotação da plataforma. Um exemplo do processo de upload pode ser visto na imagem abaixo:








Após carregar suas imagens no Roboflow, o próximo passo é atribuí-las para anotação. A anotação é um processo crucial na criação de um DataSet personalizado, e o Roboflow facilita isso com sua interface intuitiva. Basta desenhar caixas delimitadoras ao redor dos objetos de interesse, e a ferramenta salvará automaticamente as anotações. Depois de anotar suas imagens, uma caixa de diálogo aparecerá, permitindo que você divida as imagens em conjuntos de treinamento, validação e teste. É recomendável ter pelo menos 60–70% dos seus dados como dados de treinamento, pois isso fornece ao modelo exemplos suficientes para aprender. No entanto, a divisão pode ser ajustada para atender às suas necessidades específicas. Com a ferramenta de anotação do Roboflow e os recursos de gerenciamento de dados fáceis de usar, criar um DataSet personalizado para tarefas de detecção de objetos nunca foi tão fácil.
Para demonstrar o processo de upload de imagens para anotação, selecionei aleatoriamente imagens. Essas imagens são usadas como exemplos para ilustrar o processo de anotação no Roboflow.




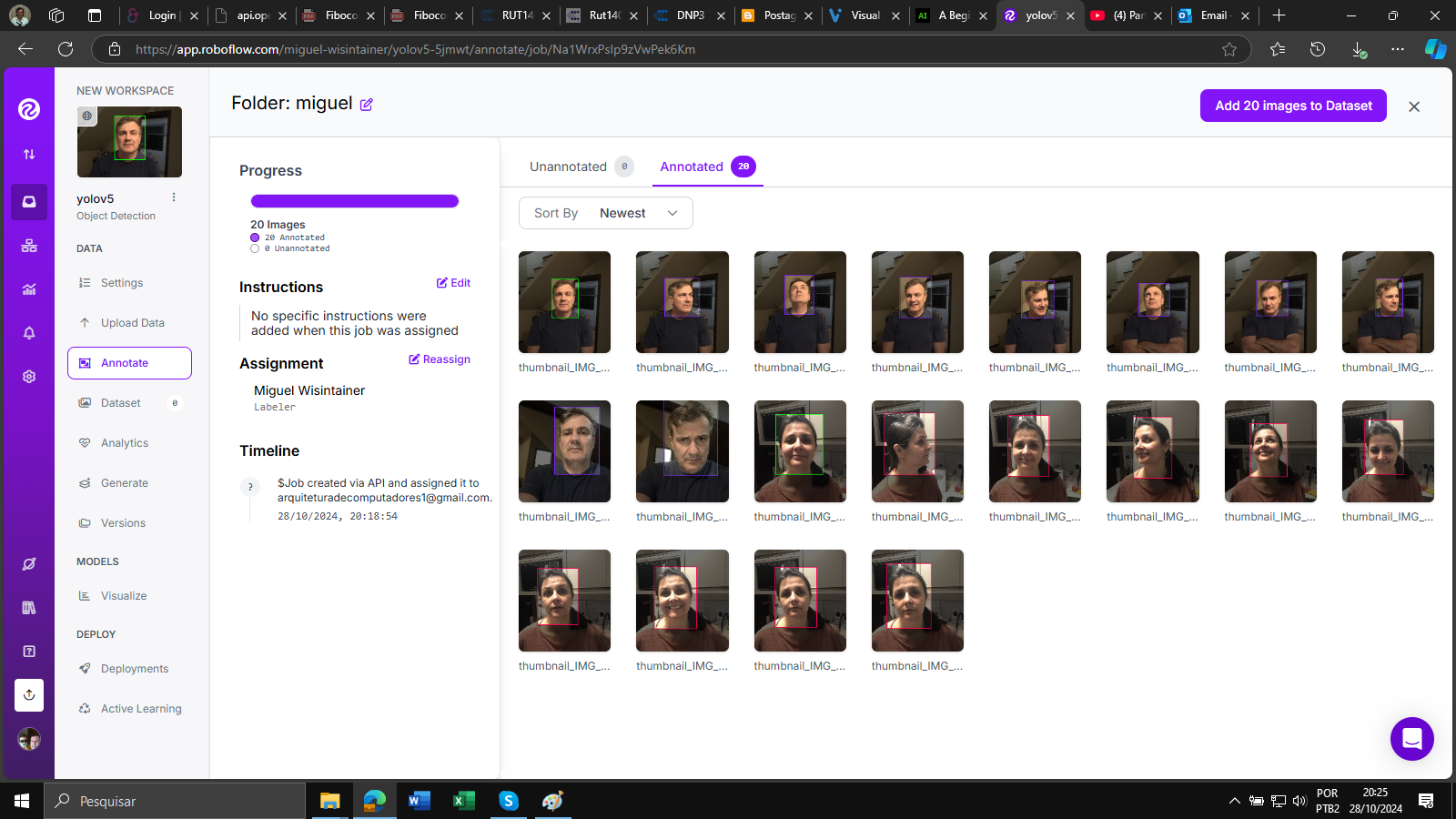

Após concluir o processo de anotação, você pode criar um DataSet dividindo as imagens anotadas em conjuntos de treinamento, validação e teste (train, valid, test):

Para fazer o treinando, foi baixado um projeto do RoboFlow Universe com as imagens já prontas para treinamento.
recognition-of-direction-arrows-for-autonomus-car-bvimf
recognition of direction arrows for autonomus car Object Detection Dataset by Florian Demolder
É hora de exportar para seu IDE local ou Google Colab.
train-yolo11-object-detection-on-custom-dataset.ipynb - Colab
Durante o processo de geração, você pode escolher as etapas de pré-processamento e aumento de acordo com seus requisitos. Por exemplo, você pode redimensionar as imagens ou aplicar técnicas de aumento de dados, como rotação ou inversão, para aumentar a diversidade do DataSet. Assim que o processo de geração for concluído, você pode exportar facilmente seu DataSet e usá-lo para treinar seu modelo de detecção de objetos.








OPCIONAL, POIS TEMOS QUASE 700 IMAGENS




Após gerar uma nova versão do DataSet, o próximo passo é exportá-lo em um formato adequado para treinar o modelo. O Roboflow oferece a flexibilidade de exportar o DataSet em vários formatos, incluindo o formato YOLO11 Pytorch (.pt), que usaremos neste exemplo. Este formato é amplamente usado para treinar modelos de detecção de objetos e é compatível com estruturas populares de aprendizado profundo (Deep Learning), como o PyTorch. Depois de selecionar o formato de exportação desejado, o Roboflow gerará um link de download para o DataSet exportado. Você pode usar este link para baixar o DataSet para seu IDE local ou Google Colab para processamento e treinamento adicionais.

É crucial salvar o link de download gerado após exportar seu DataSet em um arquivo de texto para fácil acesso, especialmente se você planeja usá-lo em um notebook do Google Colab.

Escolha YOLO11 e depois renomeie para train_data.zip para facilitar o entendimento abaixo.
Agora que preparamos nosso DataSet, é hora de mergulhar na parte emocionante do processo de detecção de objetos: treinar o modelo. Esta etapa é onde o algoritmo aprende a identificar e classificar objetos em imagens, permitindo que ele faça previsões precisas em dados não vistos. Então, vamos começar!
Treinamento de modelo
Neste artigo, usaremos o Colab para treinar o modelo de detecção de objetos YOLO11n em nosso DataSet personalizado. O Google Colab é uma plataforma poderosa e fácil de usar para treinar modelos de aprendizado profundo. O primeiro passo para começar a usar o YOLOv11s no Colab é clonar o repositório GitHub do YOLO11. Este repositório contém todo o código e os arquivos de configuração necessários para treinar o modelo. A clonagem do repositório pode ser feita executando um comando simples no notebook do Colab:
train-yolo11-object-detection-on-custom-dataset.ipynb - Colab
Comece instalando as ferramentas da ULTRALYTICS

%pip install "ultralytics<=8.3.40" supervision roboflowimport ultralyticsultralytics.checks()
Após clonar o repositório YOLOv11s GitHub, precisamos configurar o ambiente e configurar o modelo para treinamento. Isso envolve várias etapas, como instalar as dependências necessárias, configurar os caminhos para o DataSet e os arquivos de configuração do modelo e especificar os parâmetros de treinamento, como tamanho do lote, taxa de aprendizado e número de épocas.
Após configurar o ambiente, o próximo passo é copiar o arquivo que foi gerado e salvo em do seu notebook Colab. Depois de colar o código, você pode executá-lo para baixar o DataSet e carregá-lo no seu ambiente Colab. Isso permitirá que você comece a treinar seu modelo YOLO11 usando os dados anotados.

Agora é hora de fazer o "Unzip" do arquivo ZIP
!unzip train_data.zip

Iniciar o treinamento
Consulte o data.yaml e você verá o seguinte conteúdo, são 4 conjuntos de imagens que devem ser treinadas, que são as flechas.
Agora temos que mandar treinar, execute o Script Python abaixo e aguarde o treinamento.
!yolo task=detect mode=train model=yolo11n.pt data=data.yaml epochs=200 imgsz=640
!yolo task=detect mode=train model=yolo11n.pt data=data.yaml epochs=200 imgsz=640

Neste comando, podemos especificar os seguintes parâmetros:
imgsz: O tamanho das imagens de entrada durante o treinamento. Aqui, estamos configurando para 640x640 pixels.epochs: O número de épocas para treinar. Aqui, estamos definindo para 100.data: O local do arquivo YAML do DataSet que criamos no Roboflow.- mode: operação treino
model: modelo base de treino
Depois que executarmos esse comando, o processo de treinamento começará e poderemos monitorar o progresso no notebook Colab.

Durante o processo de treinamento, o YOLO11 salva dois tipos de arquivos de checkpoint:
last.pte best.pt.

last.pté o último checkpoint salvo do modelo. Ele é atualizado após cada época de treinamento e contém os pesos do modelo naquele ponto do processo de treinamento. Este checkpoint pode ser usado para retomar o treinamento de onde ele foi interrompido ou para avaliar o desempenho do modelo em uma determinada época.
best.pté o ponto de verificação que tem a melhor perda de validação até agora. Ele é atualizado sempre que a perda de validação melhora e contém os pesos do modelo naquele ponto. Este ponto de verificação é útil para seleção de modelo, pois representa o ponto no processo de treinamento em que o modelo teve o melhor desempenho no conjunto de validação. Ambos last.pte best.ptpodem ser usados para inferência após a conclusão do processo de treinamento.
O arquivo .pt pode ser baixado do Google Colab para sua máquina local apenas clicando sobre o mesmo.
Este arquivo contém os pesos do modelo de melhor desempenho durante o treinamento. É importante salvar este arquivo em um local seguro, pois ele representa o modelo treinado e pode ser usado para fazer previsões em novas imagens ou para continuar treinando o modelo mais tarde.
Se COLAB venceu, faça treinamento no ambiente DuoCPU do DOCKER, mas seja paciente com a velocidade.

É hora de exportar para CviModel, recomendo utilizar o Script (Colab) gerado por JJ.
HORA DE PORTAR PARA O MILK-V :) - COLAB
Localização do código Duo256M yolov8: sample_yolov8.cpp
(o mesmo deve ser compilado para o DUO 256)
Método de compilação
Consulte o método do link Introdução para compilar o programa "sample".
Não esquecer de mudar a linha
yolov8_param.cls = XXX;
onde XXX é o número de CLASSES, no caso acima 3, pois são 3 espécies de BUGGIO.
Após a conclusão da compilação, o programa sample_yolov8 que precisamos será gerado no diretório sample/cvi_yolo/
COLAB - do .PT para .CVIMODEL
Baixe SCRIPT para conversão
Abra no colab

Siga o roteiro, incluindo os JPG quando necessários para conversão.












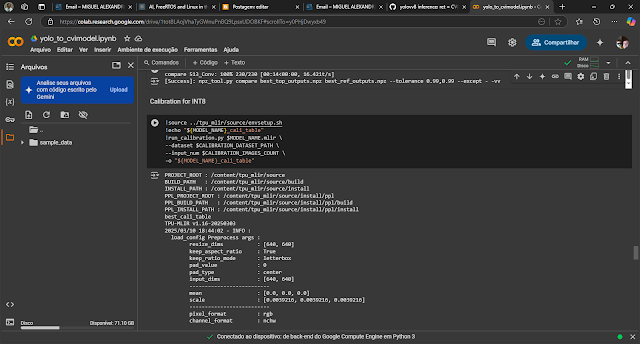





Após a conclusão da compilação, um arquivo chamado best_int8_class.cvimodel será gerado.
Transferindo para Duo 256
Copie o sample_yolov8 compilado, o cvimodel e a imagem jpg a ser inferida, para a placa e execute o programa binário:
scp best_int8_class.cvimodel root@192.168.42.1:/root/
Execute o seguinte comando:
./sample_yolov8 ./yolov8n_cv181x_int8_sym.cvimodel Ades_1-5_jpg.rf.a6adaadb480fc623707d0b53172472c3.jpgExemplo de uma imagem a ser reconhecida
Testes
[root@milkv-duo]~# ./sample_yolov8 best_int8.cvimodel norte_jpg.rf.01d03d94705ca
aac1f2f0191bccd4e69.jpg
[56319.218873] vb_ctrl:1000(): vb has already inited, set_config cmd has no effect
asign val 0
asign val 1
asign val 2
setup yolov8 param
************************
4
************************
setup yolov8 algorithm param
yolov8 algorithm parameters setup success!
---------------------openmodel-----------------------
---------------------to do detection-----------------------
image read,width:640
image read,hidth:640
objnum: 1
boxes=[[0.000000,103.103699,639.000000,591.668213,1,0.959542],]
[root@milkv-duo]~#
[root@milkv-duo]~# ./sample_yolov8 best_int8.cvimodel sul_jpg.rf.10caea3f240d047
9256354c786c619e7.jpg
[56370.558113] vb_ctrl:1000(): vb has already inited, set_config cmd has no effect
asign val 0
asign val 1
asign val 2
setup yolov8 param
************************
4
************************
setup yolov8 algorithm param
yolov8 algorithm parameters setup success!
---------------------openmodel-----------------------
---------------------to do detection-----------------------
image read,width:640
image read,hidth:640
objnum: 1
boxes=[[0.000000,51.852066,546.493713,634.700317,3,0.978451],]
[root@milkv-duo]~#
[root@milkv-duo]~# ./sample_yolov8 best_int8.cvimodel oeste_jpg.rf.0aaf30643b4dc
72a423ecad27318822f.jpg
[56403.524907] vb_ctrl:1000(): vb has already inited, set_config cmd has no effect
asign val 0
asign val 1
asign val 2
setup yolov8 param
************************
4
************************
setup yolov8 algorithm param
yolov8 algorithm parameters setup success!
---------------------openmodel-----------------------
---------------------to do detection-----------------------
image read,width:640
image read,hidth:640
objnum: 1
boxes=[[123.591751,65.452927,639.000000,594.583862,0,0.891947],]
[root@milkv-duo]~#
[root@milkv-duo]~# ./sample_yolov8 best_int8.cvimodel leste_jpg.rf.0eb2bc67b0858
602b1fc15975bb974e3.jpg
[56439.584750] vb_ctrl:1000(): vb has already inited, set_config cmd has no effect
asign val 0
asign val 1
asign val 2
setup yolov8 param
************************
4
************************
setup yolov8 algorithm param
yolov8 algorithm parameters setup success!
---------------------openmodel-----------------------
---------------------to do detection-----------------------
image read,width:640
image read,hidth:640
objnum: 1
boxes=[[0.702728,59.135406,552.091187,523.303955,0,0.940490],]
[root@milkv-duo]~#
Referência (Tradução) e testes com MILK-V
Blogs SmartCore
Sobre a SMARTCORE
A SMARTCORE FORNECE CHIPS E MÓDULOS PARA IOT, COMUNICAÇÃO WIRELESS, BIOMETRIA, CONECTIVIDADE, RASTREAMENTO E AUTOMAÇÃO. NOSSO PORTFÓLIO INCLUI MODEM 2G/3G/4G/NB-IOT, SATELITAL, MÓDULOS WIFI, BLUETOOTH, GPS, SIGFOX, LORA, LEITOR DE CARTÃO, LEITOR QR CCODE, MECANISMO DE IMPRESSÃO, MINI-BOARD PC, ANTENA, PIGTAIL, BATERIA, REPETIDOR GPS E SENSORES
Assinar:
Comentários (Atom)